
The Zeebe team is excited to announce the 0.12 release. To get started with Zeebe 0.12, please see our installation guide.
It’s been 3 months since the Zeebe 0.11 release, and we’ve been hard at work adding new BPMN symbols that will enable Zeebe to support a range of new use cases.
The 0.12 release also includes a number of architectural changes to Zeebe that make it a much simpler system that’s more focused on its core use case: high-throughput, low-latency workflow automation.
We’ll cover those architectural changes at a high level in this announcement, and we’ve also published a separate blog post with more detail. In the rest of this post, we’ll cover the highlights of the 0.12 release as a whole.
BPMN Symbols: Message Events and Message Correlation
Zeebe 0.12 includes support for BPMN’s intermediate message catching event and Receive task. These BPMN symbols will allow Zeebe to operate within an event-driven architecture, where a workflow might need to react to events that are created by external systems then published to a messaging platform such as Apache Kafka or Amazon Kinesis.
By using a message correlation ID, Zeebe can identify the specific workflow instance that a message belongs to–and this mapping of message to workflow instance is handled entirely by Zeebe, with no heavy lifting required by the user.
Let’s walk through an example. Imagine we’re an e-commerce company that uses the following new account activation workflow.
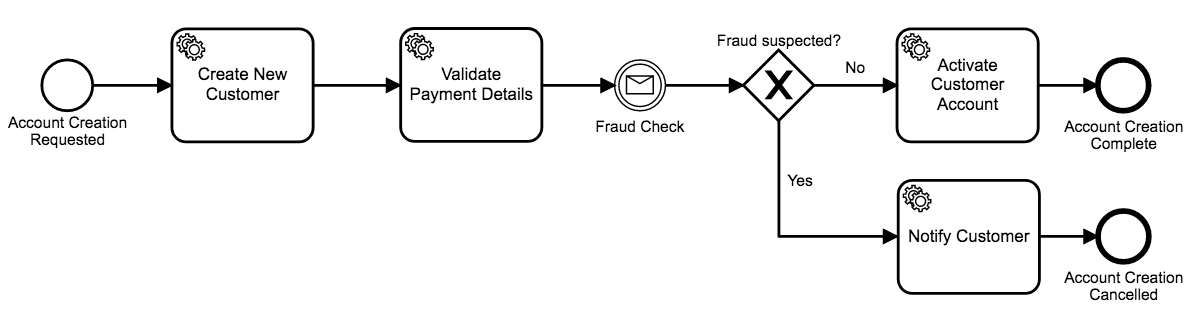
First, we have an account service that creates a new customer account with a name, email address, and password. Next, we ask the customer to input payment details, and our payments service runs a quick validation on the customer’s payment method.
Before we activate the customer account, though, we wait for a system powered by an external security vendor to check the account and payment details and alert us if the account might be fraudulent.
For all new accounts that are created, this security system publishes a message indicating “fraud suspected” or “no fraud suspected”, and every workflow instance waits until it receives this message before progressing to the final step. Depending on the payload of the fraud message, we either activate the account or notify the customer that their account could not be activated.
When we say that Zeebe supports message correlation, in this example, we mean that Zeebe is able to map these incoming fraud notification messages to the correct workflow instance based on a common identifier. Message correlation is an important concept in Zeebe, and we’ll be dedicating an entire blog post to this subject in the near future–stay tuned.
In the meanwhile, to learn more about working with messages in Zeebe, please see the documentation.
BPMN Symbols: Parallel Gateway and Embedded Subprocess
In addition to messages, Zeebe now supports two more BPMN symbols: the parallel gateway and the embedded subprocess.
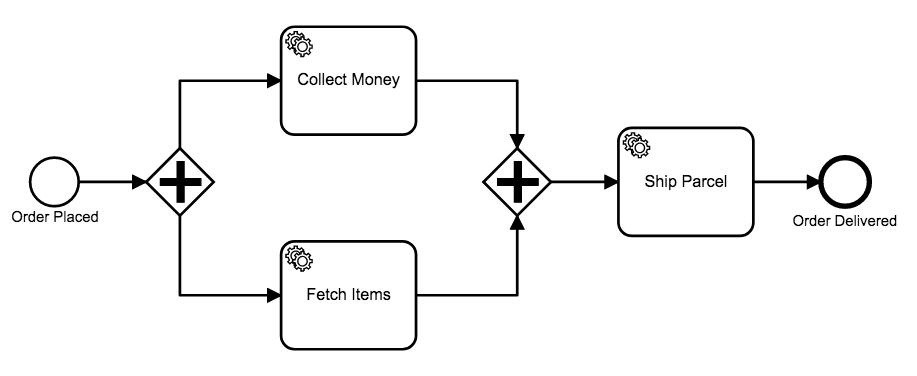
The parallel gateway is used to model concurrency in a workflow. There are many cases when tasks that are carried out by different services can be executed at the same time. In the e-commerce order fulfillment example that we reference throughout the docs, we might want to collect a payment and fetch the items in parallel rather than sequentially. So a process that looks like this:

Can be modeled and executed like this instead:
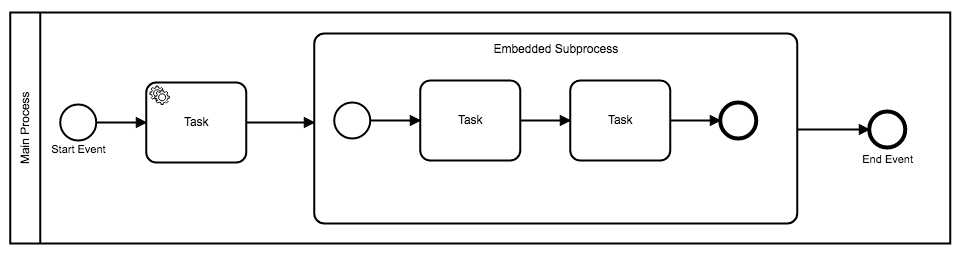
The embedded subprocess is used to represent a process that’s defined completely within a parent process. As of 0.12, the feature can be used to create clearer models, and once we’ve added support for boundary events (scheduled for Q42018), the embedded subprocess can provide a new level of scope for events within or attached to the subprocess.
Zeebe Data Exporter (with out-of-the-box support for Elasticsearch)
Zeebe 0.12 introduces a new exporter system that makes it easy to stream historic workflow data out of Zeebe and into a storage system of your choice–for example, a Kafka topic or Elasticsearch.
And speaking of Elasticsearch, we’ll be providing a ready-to-use Zeebe exporter to move historic workflow data from Zeebe into Elastic. The Zeebe-Elasticsearch exporter is documented here.
To learn more about Zeebe exporters, please see the documentation.
Zeebe’s new exporter feature is one piece of the conceptual changes we’re introducing in the 0.12 release. So next, we should discuss…
Conceptual Changes in Zeebe 0.12
Shortly after the 0.11 release in July, we took a step back to reconsider the scope of the problem that Zeebe should solve, and therefore, how Zeebe should be built.
As a result of this review, starting with 0.12, Zeebe is a simpler system with a sharper focus on solving core workflow automation and microservices orchestration use cases and will intentionally not address other use cases such as long-term data storage.
We wrote a separate blog post to describe these changes to Zeebe in more detail.
To summarize what’s new starting in 0.12:
- No more topics – Zeebe is now a single-topic system: Zeebe previously supported multiple dynamically-created, partitioned topics for multi-tenancy. Multi-tenant systems, however, are significantly more complex than static systems, and existing tools such as Kubernetes already solve for isolation and resource management.
- Topic subscription has been replaced by exporters: Previously, Zeebe could be used as a long-term data store, and external systems would pull data out of Zeebe topics as necessary. Instead, Zeebe now provides an exporter interface that makes it easy to stream historic workflow data into a storage system of your choice. And Zeebe will remove data that’s no longer needed for execution of active workflows.
- Introduce RPC clients and a gateway: Previously, Zeebe clients were relatively heavy, with logic duplicated in each client. There was a complex, multi-layer protocol, and a client needed access to every broker in the cluster. Starting in 0.12, Zeebe supports thin, “dumb” clients with the protocol defined in gRPC and Protobuf. These clients only require access to a stateless gateway. This means that clients in different languages will need less maintenance, and at the same time, it’ll be easier to deploy and secure a Zeebe cluster.
While we’re removing some of the functionality we’d initially planned for Zeebe–specifically, long-term data storage–we’re excited to be simplifying the system and focusing on the core use cases that Zeebe handles best. These changes will make it much easier to support and improve Zeebe both now and in the future.
If you’d like to learn more, please check out the blog post about these changes, and if you have questions or feedback, we would love to hear from you.
What’s Next for Zeebe?
In Q4 2018, a top priority is adding support for more BPMN symbols. We’ll be working on the timer event and boundary events (specifically, interrupting and non-interrupting timer and message boundary events). Our planned BPMN work also includes timer and message start events.
We’ll also invest time in hardening other Zeebe components to prepare for production-readiness. Areas of focus are payload handling, incident handling, clients, and the CLI.
We’re really happy to be putting the 0.12 release out there, and we expect that it’ll open up a range of new use cases for those of you who have been waiting to start prototyping with Zeebe.
And we’re eager to hear your feedback. Please take a look at our Community page to see how you can get in touch with us.