
“There is a lot of valuable information in this Slack, but whenever I come back to find it, it’s gone because of the 10,000 message limit. Can we move this community to Discord, which has persistent message history?”
That message, from a community member in the Zeebe Slack, triggered a DevRel project that resulted in the Slack Archivist – a Slack bot that allows valuable conversations to be archived from the community Slack to a dedicated searchable topic in our Discourse-powered Forum.
The Problem
Slack is ubiquitous. You probably have it open right now, and are in several different Slack teams.
We use Slack internally at Camunda, on a paid plan, and when it came time to stand something up for our then-experimental foray into an open source cloud-native workflow engine, we stood up YAST – “yet another Slack team“.
On the free tier, only the last 10,000 messages are available. This means in high-volume Slack teams, community interactions and shared knowledge is lost.
We looked at moving to a paid Slack subscription (too expensive), or moving to Discord (too disruptive), and settled on writing a bot that archives valuable conversation threads to our Discourse-powered forum in a dedicated category “Knowledge from Slack”.
The Solution
The Slack Archivist can be invoked by any user by tagging the bot in a conversation thread in Slack, and providing a title for the post. When the bot gets tagged, it pulls the entire thread from the Slack API – along with any images – and builds a markdown post for Discourse.
This gets posted to Discourse via the API, and the Archivist posts a link in the thread:
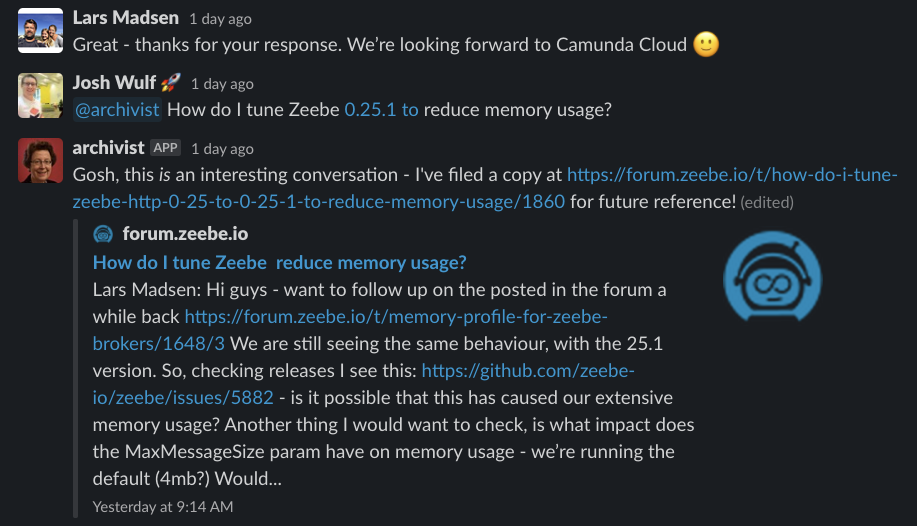
After rolling up the thread and posting it to the Forum, the Archivist keeps listening to that thread, and incrementally updates the forum post with any further conversation.
By convention, we phrase the post title as a question. This is inspired by the principles of Knowledge-centric Support (KCS) – more about that below.
The bot is written in TypeScript, and uses a PouchDB database (with a LevelDown filesystem driver) to track the conversation threads it is monitoring, and which posts to update in the Forum. PouchDB is a NoSQL (JSON document) database, written in JavaScript, so it has a good impedance match with JavaScript code.
We deploy our instance of the Slack Archivist in a vanilla VM on Google Cloud, in a Docker container, using a docker-compose file to start it. The directory containing the database is mounted from outside the Docker container, so it persists state between container restarts.
The database is also used to buffer incremental updates to existing posts, using a transactional outbox pattern.
The bot uses the Slack Events API, a push notification model that calls the bot over an incoming webhook when a subscribed event occurs. It listens to all messages in the Slack team, and maintains a list of conversations that it is following.
When a message appears in a Slack conversation that has been archived to the Forum, the message gets persisted immediately as a pending update record. An async process then updates the Forum, and when this is done, marks the pending update record as “written”.
I did this – inspired by a system design that one community member shared in the Slack – to allow the bot to be redeployed without concern for losing any messages. As the number of conversations being monitored for incremental updates increases, the chances of losing something while updating the deployment rises.
This surface area of “potential data loss” is more than milliseconds, because the Slack Archivist uses a Rate Limiter on API calls to Discourse, to avoid saturating the API. The Rate Limiter on the bot’s Discourse API buffers calls in-memory and executes them at a maximum rate of three per second.
The volume of calls to the Discourse API is proportional to the number of conversations being tracked, the volume of messages in those conversations, and the number of new conversations being archived. Incremental updates to the Forum could be buffered for seconds, depending on the volume. So they get immediately persisted to the database, and then buffered in-memory by the rate-limited async update process.
When the bot is down, redeploying, Slack will retry the push notifications of new messages until it comes back up. If it stays down too long, then Slack will give up and mark it as “bad”. Then it needs to be reinstalled in the Slack team. But the ./rebuild.sh script in the repo, used for deploying an update, brings the bot down for less than a minute – so Slack’s buffering works in this case.
Knowledge-centric Support (KCS)
We set out to solve the problem of the continual erosion of our community’s collective intellectual capital – the insights and experiences that get shared in Slack conversations.
We did that, and it opened up further intriguing possibilities.
This is the part where we go from technical details to aspirational vision. Feel free to drop out and dig into the source code for the Slack Archivist if that’s of greater interest.
Knowledge-centric support is a model for fusing knowledge across conversations to create and leverage network effects. I’ve encountered it before in a support organization setting, but we can also leverage the principles for community support. And the Slackbot is an excellent first step in that direction.
Let me introduce KCS to you with an anecdote from my days in a support organization.
Picture this:
It’s 8am on the East Coast of Australia, and the Brisbane-based team takes the hand-off from the US as part of the follow-the-Sun support.
As soon as I log in, the phone rings. A customer is having trouble logging in to a server. We go through a fault-diagnosis tree, narrowing things down to more and more improbable scenarios. Thirty minutes go by, and we are unable to figure it out. I’m frustrated, because I should be able to solve this. But, finally, I bite the bullet and we move it into a ticket for asynchronous support. I get off the call, and get another one. I notice that the others in the support team are all on calls too.
The next caller has the same issue. This is weird. I put them on hold, then hit up Gene, who is sitting next to me, and just got off a call. “Hey, have you had anyone unable to log in to a server?”
“Yeah, I just got off a call for that. Couldn’t figure it out.”
It turns out that everyone had been supporting customers with that same issue. A package update had broken something in the log rotation, and with the machine out of disk space, no interactive sessions could start.
It took us longer to identify a systemic issue because we had multiple people supporting it in parallel, with no idea that it was widespread. That additional contextual information alone would have enabled us to diagnose it much faster.
KCS A-loop: Making knowledge shared and discoverable
When KCS is introduced, the first practice is to immediately open a ticket in the system using the language of the customer to describe the problem. The system then shows you all open support tickets that resemble that problem. If one looks like it, you update that ticket. With that, as soon as the second call came in, we would have been working on the same problem. As soon as the third call came in, it would have been obvious – in the first fifteen minutes of the day – that we were dealing with a widespread systemic failure, rather than an individual case.
This is the KCS “A-loop”, a feedback loop where community members with knowledge and community members with questions swarm issues in the same “knowledge space”, leveraging a network effect.
In a support setting, there are experts who generate and have access to the knowledge, and the customers do not. In a community setting, the knowledge is generated by the community and is accessible to them. Rather than phoning an expert, community members search the Forum.
“Using the language of the customer” is crucial.
Engineers often phrase titles as solutions, or causes. But customers / community members do not come looking for an identified cause. They come with a problem. This was summarized well in one of the internal mailing lists, where a kernel engineer pointed out that users are not searching for a bug report titled “Nouveau driver fails to load on kernel 4.14“. They are looking for “Why is my screen blank?“.
The titles of the posts in the “Knowledge from Slack” category are phrased in the language of the community, using our best estimation of what someone else with this same problem is looking for. It is about making the knowledge not only persistent, but discoverable.
We are able to leverage the real-time communication and discussions of our community into a long-tail knowledge base of content that answers the questions that community members have. Not every Slack conversation is worth archiving. Sometimes they are community members shooting the breeze, or announcing something that is specific to a timeframe. But some conversations turn into valuable knowledge – the kind of thing that gets missed when it scrolls over the 10,000 message event horizon. Now, we get the benefits of immediacy in Slack, and retention in the Forum. It takes the value of the knowledge sharing conversations in Slack, and adds it to the Forum, increasing the value of both.
The next step for the Slack Archivist is for it to mine the accumulated knowledge. This can be done by adding a query interface, where community members can ask a question, and the Slack Archivist can suggest archived conversations in the Forum that might be relevant. A further interesting possibility is to detect a question, and see if we can suggest a relevant solution in a DM.
In this way, we take the value of the posts in the Forum and add it to Slack, closing the loop and creating a virtuous circle.
And what about if we add GitHub? How many times have I answered a query with “See this issue in GitHub“?
KCS B-loop: Detecting and addressing product issues
The KCS B-loop is where support hits documentation / engineering.
Some problems are not issues like a bug in the log rotation package, but rather some usability issue or missing step in documentation, or a poorly designed system feature. As a support technician (or Developer Advocate), you can find yourself in a Ground Hog day of walking people through the same thing over-and-over again, starting with “oh that! Yeah, it’s missing this context / this step / has this confusing option“.
The KCS B-loop creates a longer feedback loop between support and engineering. These kinds of “common support issues” are analyzed from the support system, and converted into fixes for the product or documentation.
With the “Knowledge from Slack” category of the forum, we have the opportunity to measure the usefulness of a piece of knowledge across the community. Obviously it was useful to at least one community member in Slack. But is it something that many people are interested in?
Is it missing in documentation, or do we need to make it more discoverable or clearer in there? Is it a product feature that should be pushed as feedback to product management? Is it a popular use-case that would benefit from a technical article or tutorial?
At the moment, we measure this by the engagement with the post in the Forum. If we add the query interface / suggestion wizard, we can also get a score on the relevance from that.
This longer feedback cycle allows us to see and analyze patterns in product design that would otherwise be a picture whose pieces were scattered across multiple interactions and multiple people.
Advocacy Engineering
As a Developer Advocate, my role synthesizes all of the previous roles I’ve worked in: support, documentation, and engineering. I’m community-facing and engineering-facing. The DevRel team advocates for Camunda to developers, and advocates for developers to Camunda.
Building the Slack Archivist has been a fulfilling project. Seeing community members trigger it to post content from Slack to the Forum for their future self and for others is rewarding. It brings self-interest and community benefit together in alignment.
And, I love to code. 🙂
Start the discussion at forum.camunda.io