
BLUF (Bottom-line Up-front): GitHub Actions are AWESOME and will change your life, but you risk losing yourself in a microservices architecture of repos, or have to go monolith once you get a few dependent projects or cross service provider boundaries – unless you orchestrate. I show you how I did it in this article.
Get access to the Camunda Cloud Public Access Beta here. Use the Zeebe GitHub Action to orchestrate multi-repo builds with Zeebe and Camunda Cloud.
In this article:
- Preamble
- What are GitHub Actions?
- GitHub Actions: The Good
- GitHub Actions: The Bad
- GitHub Actions: The Ugly
- Custom CI with GitHub Actions and Camunda Cloud
- Zeebe GitHub Action
- Modelling the problem / solution
- Starting a Camunda Cloud workflow from GitHub
- Passing around an encrypted GitHub token
- Setting up Camunda Cloud to access the GitHub API
- Passing in a secret from Worker Variables
- Using workflow variables as string constants
- Triggering a GitHub workflow from Camunda Cloud
- Problems accessing the GitHub API
- Communicating a GitHub Workflow outcome to Camunda Cloud
- GitHub Matrix builds
- Multiple causes for an action
- Specialising HTTP Worker payloads
- Specialising GitHub Workflows
- Ad Infinitum: To Infinity, and Beyond!
- Live Stream
Preamble
Over the weekend, I did some work on an side-project, Magikcraft. It’s a platform for teaching kids to code in JavaScript, and it builds on an excellent Open Source project called ScriptCraft, written by Walter Higgins.
Since Microsoft bought Minecraft, the pace of development has increased, and there have been a lot of breaking changes to the APIs. Oracle have also deprecated the JavaScript engine – Nashorn – that we have been using since JDK 8, and introduced their new polyglot engine GraalVM.
Testing on and supporting all the various combinations of Minecraft server versions and JS runtimes has stretched the capacity of the ScriptCraft community, but there are many passionate users, including other downstream kids coding programs, like Code Makers, that use it.
It got to a breaking point with the latest Minecraft release, when a workaround patch we’d been relying on finally stopped working, and Walter let us all know that he was strapped for time and attention to give to the project. So I chipped in and built an automated building and testing infrastructure using GitHub Actions.
What are GitHub Actions?
“GitHub Actions” is the overall name given to a workflow automation capability on GitHub. I suppose it is not called “GitHub Workflows” because that namespace is already taken by the git-flow kind of stuff.
You have workflows, which you define in YAML files in a .github/workflows folder in your GitHub repo. These workflows contain named jobs, which are made up of 1 or more named steps. The steps can use GitHub Actions, which are reusable modules of functionality, providing capabilities like installing build chains and runtimes, executing Docker commands, and so forth.
GitHub Actions: The Good
GitHub Actions let you define workflows in YAML that run in response to actions like a git push. You can use one of the many existing actions, or build your own.
The workflows run on Azure – no surprise there, since Microsoft bought GitHub. What was a surprise to me, however, is how fast they run. I created a matrix build that builds and publishes nine – yes, 9 – Docker images to Docker Hub. The equivalent build on Docker Hub takes up to an hour. On GitHub, it is done in minutes. There are some serious compute resources available on there.
It is so much faster that I moved the Docker image builds from Docker Hub’s automated builds to GitHub Actions using the Publish Docker GitHub Action.
GitHub Actions: The Bad
You can’t validate or test your workflows without pushing them to GitHub. There is no local executor like there is for CircleCI, and while there is a validator plugin for VS Code, I couldn’t get it to give me “required parameter” feedback for the Zeebe GitHub Action that I created.
This is offset by how fast GitHub Actions run, so the code-execute-debug cycle is bearable. If it weren’t this fast, that would be a serious problem – but I actually enjoyed the power of so much compute resources dedicated to Open Source while debugging, so it kept me going.
YAML – meh, as one product owner told me over dinner at the recent DevConf.CZ: “It’s the least worst thing we’ve come up with so far“, paraphrasing Churchill’s take on democracy. Of course, I was like: “Have you heard of this thing called BPMN?“
Sidenote: when I started teaching kids to code, many were using this thing called Scratch, which is a block-based programming language. I turned my nose up at it, saying: “That’s not real programming“, and proceeded to teach them the difference between ) and } and where to find them on the keyboard – like that’s real programming. My “Road to Damascus” moment was when an 8-year old kid came in and I coached him through making a combination lock guessing game, and he built a working prototype in thirty minutes with Scratch – because he was dealing purely with the logic of the program, and not struggling with syntax errors. The trickiest thing for him was state management, not balancing the right type of brackets.
GitHub Actions: The Ugly
Part of my contribution upstream to ScriptCraft has been integration with NPM, the JavaScript packaging ecosystem. The purpose of that is to unlock the innovation of the community to create, share, and discover others’ work – an essential dynamic in a vibrant Open Source community.
So, once I got automated builds, unit testing JavaScript in a dockerized Minecraft server in a GitHub action (seriously – your workflow can run for up to six hours – you could play Minecraft in a GitHub action), and publishing test images to Docker Hub, the obvious next question is:
How do I trigger a test run for downstream dependent packages when I publish a new image of the core API?
Yes, you can trigger GitHub actions in a downstream repository via webhook configuration (there is even a GitHub Action for it), but now you enter the rabbit hole of peer-to-peer choreography, with an attendant loss of visibility.
Is everything wired up? When you walk away from it for a week or two, or a month, and come back – how do you remember how it is all hooked up? Where do you go for the single point of truth for the system?
Even with three layers (base image, release package, image with release), and one dependent package, I’m having trouble remembering what triggers what and how.
“I push to this GitHub repo, that triggers Docker Hub, when that is done it should trigger a retest and rebuild of this other layer on GitHub, and that should then publish to Docker Hub, which should trigger all downstream package tests.” Pretty straight-forward, no? No.
Documentation is one attempt to address this – but is that really going to stay up to date?
Devolving responsibility is another way – package maintainers are responsible for triggering their own rebuilds / retesting. But again, there is a tight coupling to automate that, and it is opaque. And I already know that when I walk away from the small part that is already implemented, I will forget how it works and curse the idiot who wrote the documentation because it doesn’t make sense.
This is not a problem with GitHub Actions really, it is a characteristic of any complex system with multiple stakeholders, integrating disparate systems, with limited resources.
Custom CI with GitHub Actions and Camunda Cloud
It was right about then – 2am in the morning – that I remembered Ruslan’s recent article “Quick Serverless start to Camunda Cloud Public Beta“.
In the list of example use cases at the start he included “Custom CI/CD“.
Now, I always thought the “custom CI” example was contrived – I mean, isn’t that what CI systems literally do? Don’t they have this stuff built-in?
Spoiler: Yes, they do – but often using peer-to-peer choreography, and without a dependency graph – especially when you start to scale across a community or an ecosystem, or even just multiple service providers.
Zeebe GitHub Action
To solve this multi-repo build automation with Camunda Cloud, I wrote a Zeebe GitHub Action. It bundles the Zeebe Node client into a single file, and allows you to use it with declarative YAML in GitHub workflows to create workflow instances and publish messages back to Camunda Cloud from within GitHub Actions.
Modelling the problem / solution
OK, so let’s do this.
We going to create executable documentation of the system architecture that cannot go out of date, and crystallize it with the minimum number of moving parts to scale to more dependent packages.
We can use the GitHub API v3 – it’s an old school REST API left over from the days before GraphQL. It will give the whole thing a retro vibe, and we can call it directly from Camunda Cloud using the built-in HTTP Worker. I’m joking! We’re going to build a custom GraphQL client. No, we are not. REST is fine, and perfectly suited for this task. We are not requesting arbitrary related data over multiple calls, or introspecting an unknown schema, so GraphQL has no benefit here.
We can trigger a GitHub workflow over the API with a repository dispatch event.
First step, I model how I want the system to behave in the Zeebe Modeler – a desktop application for creating BPMN diagrams (apparently it is XML in the background, but seriously – it’s 2020, who needs to see that stuff?):
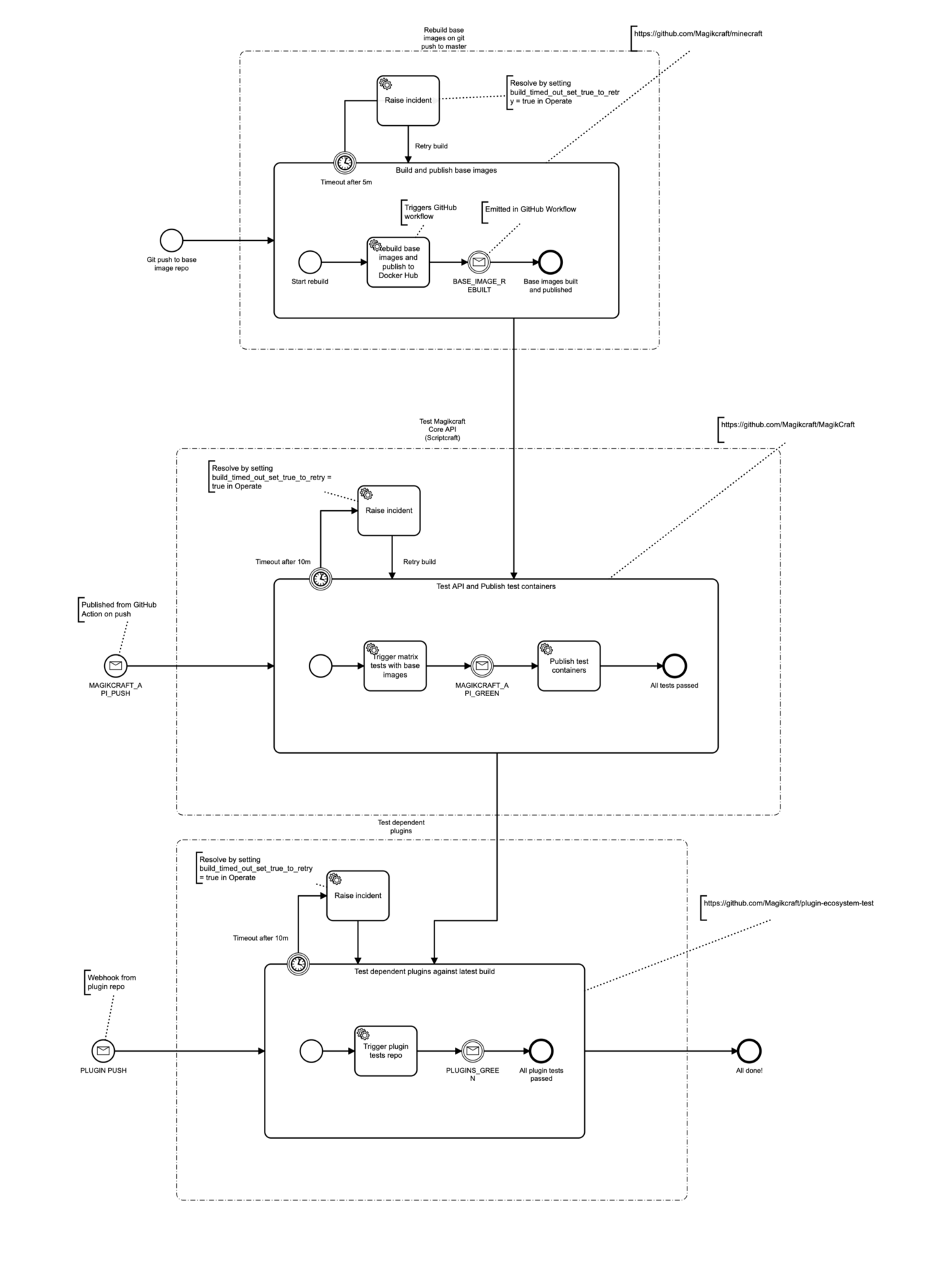
These are three dependent repositories that should trigger a rebuild / test in all downstream repos when they are updated.
The first one gets triggered in response to a push to a git repo, and has no other cause. This repo has a GitHub workflow that builds and pushes the base images to Docker Hub. When this GitHub workflow is complete, it communicates this back to Camunda Cloud by using the Zeebe GitHub Action to publish a message to Camunda Cloud.
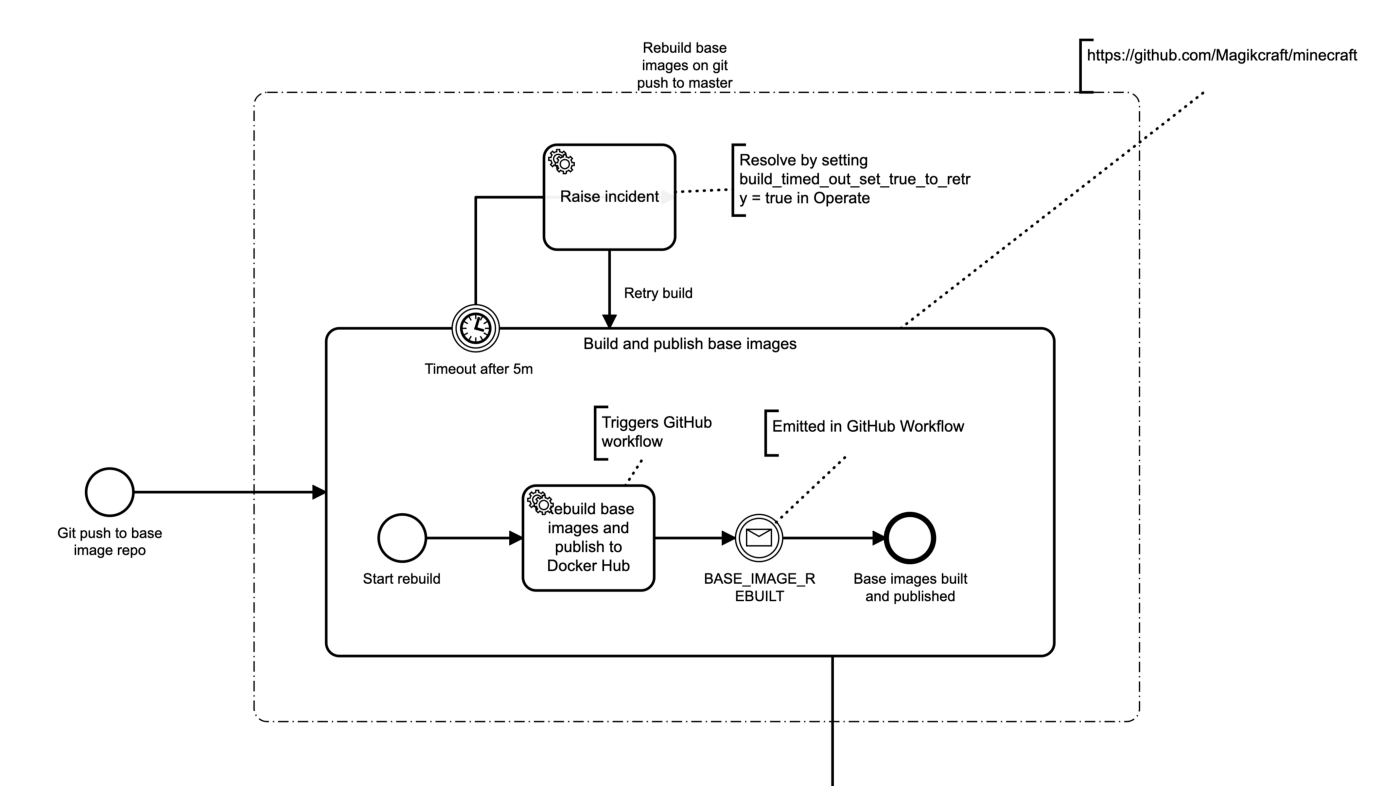
Starting a Camunda Cloud workflow from GitHub
We need to correlate this message back to the running process instance, so we need a unique correlation id. We can get one by starting the Camunda Cloud workflow from GitHub on repo push using the Zeebe GitHub Action to create a workflow instance. When we start it, we’ll pass in a unique buildid, which we will use to correlate messages to this particular workflow run (see this article for a great tutorial on message correlation in Zeebe).
Here is the GitHub workflow that is triggered by a push to the repo, and starts a workflow instance in Camunda Cloud.
name: Kick off Build Orchestration
on:
push:
branches:
- "master"
jobs:
startWorkflow:
runs-on: ubuntu-latest
steps:
- name: Get current time
uses: gerred/actions/current-time@master
id: current-time
- name: Create Zeebe Workflow
uses: jwulf/zeebe-action@master
with:
client_config: ${{ secrets.ZEEBE_CLIENT_CONFIG }}
operation: createWorkflowInstance
bpmn_process_id: magikcraft-github-build
variables: '{"buildid": "${{ github.sha }}-${{ steps.current-time.outputs.time }}", "gitHubToken": "Bearer {{GitHubToken}}", "TYPE_TEST": "TYPE_TEST", "TYPE_PUBLISH": "TYPE_PUBLISH" }'The ZEEBE secret comes from the Camunda Cloud console client configuration, and is added to the GitHub repo as secrets, so that the GitHub Actions have access to them in the secrets context.
Click the copy button in the Cloud Console to copy the entire block, and paste it as-is into a new repo secret called ZEEBE_CLIENT_CONFIG.
Passing around an encrypted GitHub token
We also need to get our GitHub Token into the workflow. We could put it into the variables of the Camunda Cloud workflow when we create it from the GitHub workflow (it is injected there as ${{ secrets.GITHUB_TOKEN }}). However, this will put it into the Camunda Cloud workflow variables in plaintext – which we would like to avoid if we can.
Luckily, we can. The Camunda Cloud HTTP Worker can store encrypted secrets and replace them at run-time from a template. So we can create a personal token on GitHub (make sure it has the repo scope). Then, add a GitHubToken secret in the HTTP Worker “Worker Variables” dialog in the Camunda Cloud Console, and put the GitHub Token in there.
Setting up Camunda Cloud to access the GitHub API
-
Log into the Camunda Cloud console.
- Go to your cluster, and click on “Worker Variables”. These are like secrets in CI systems – you can inject them by name, rather than putting secrets in your BPMN or code.
- Click on “Add Variable”, and create a new variable called
GitHubToken. Paste the token in there as the value.
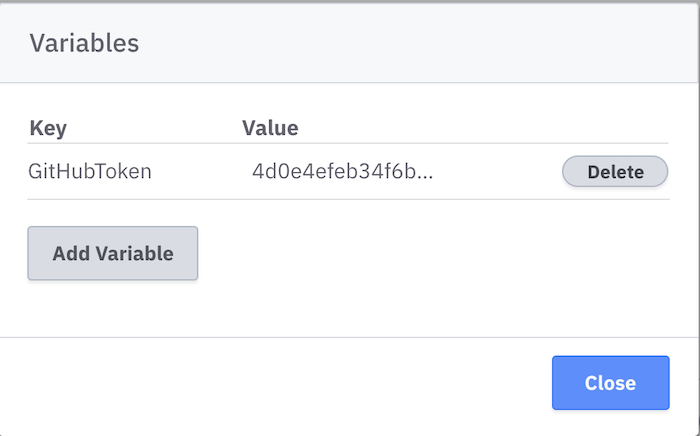
Passing in a secret from Worker Variables
When we pass in our authorization header that will use the secret Worker Variable, it looks like this in the variables payload for a createWorkflowInstance or publishMessage call:
{
GitHubToken: "Bearer {{GitHubToken}}"
}The Bearer part is important, so don’t forget it. The {{GitHubToken}} part will be templated with the value from the Worker Variables when the HTTP Worker uses this variable. I should have called this variable GitHubAuthHeader to make it clear what it is, and how it is distinct from the Worker Variable.
So you can think of it like this:
{
GitHubAuthHeader: "Bearer {{GitHubToken}}"
}The workflow’s GitHubAuthHeader variable now contains an auth header, and the HTTP Worker will template in the value of the GitHubToken secret from the Worker Variables.
So the on push workflow in the base image repo does nothing more than create a new workflow instance in Camunda Cloud, with a unique buildid for this instance, and an authorization header for our GitHub API calls, containing the name of the encrypted secret to template in at runtime, and some string constants to allow us to specialize HTTP payloads via I/O mapping. What??
Using workflow variables as string constants
We create the Camunda Cloud workflow instance with some variables that will act as string constants for us in the workflow:
{
TYPE_TEST: "TYPE_TEST",
TYPE_PUBLISH: "TYPE_PUBLISH"
}We don’t have the ability to specialize the payload of HTTP Worker calls with string constants in a BPMN model – but we can through variable mapping if we start the workflow with a known “enum” dictionary. Then we can specify a string constant by mapping one of these variables into the body.
There is always a way.
You can view this initial workflow on GitHub.
Triggering a GitHub workflow from Camunda Cloud
The first thing our Camunda Cloud workflow does is trigger another GitHub workflow in the base image repo, to rebuild and publish the base images to Docker Hub.
We trigger the workflow by posting a repository_dispatch event to the base image repo via the GitHub API, using the Camunda Cloud HTTP Worker.
The service task that does this has the task type CAMUNDA-HTTP.
It has two custom headers that are semantic for this worker: method and url.
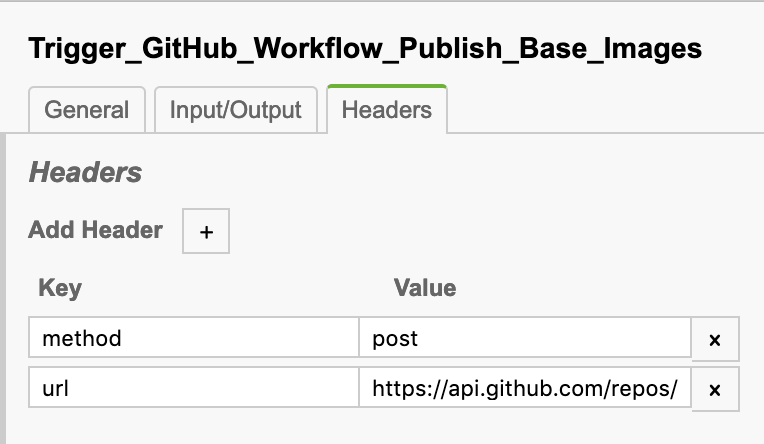
We set method to post for an HTTP POST request, and set the url to https://api.github.com/repos/Magikcraft/minecraft/dispatches for the repository dispatch event endpoint for this repo.
Two of the workflow variables are also semantic for the HTTP worker: body and authorization.
The value of body will be JSON parsed and sent as the body of the HTTP request, and the value of authorization will be sent as the authorization header.
So we create I/O mappings in the Zeebe modeler to map the variable gitHubToken (which contains our templated auth header string with GitHub token) to authorization, and the buildid (our unique correlation id) to body.client_payload.
The body.client_payload key can contain arbitrary data that will be available to the GitHub Actions that respond to this event. With access to the correlation key buildid, they can publish messages back to Camunda Cloud that are correlated to this running workflow instance.
The body.event_type key is required by the GitHub API, and here we can map one of our enum variables in: TYPE_PUBLISH. This repo does not have specialized behaviors that we need to orchestrate, so we don’t bother testing the event_type in the triggered workflow.
Problems accessing the GitHub API
If GitHub is responding with 404, if the URL is correct (double-check it!) – it means that you were not authenticated.
Typically, we send a 404 error when your client isn’t properly authenticated. You might expect to see a 403 Forbidden in these cases. However, since we don’t want to provide any information about private repositories, the API returns a 404 error instead.
- from here
You can debug this by pointing the HTTP Worker at https://webhook.site/ to see the exact payload it is sending to the GitHub API.
Communicating a GitHub Workflow outcome to Camunda Cloud
We can publish a message to Camunda Cloud from the GitHub workflow after we push the base images to Docker Hub.
Here is the section of the base image repo’s publish workflow that communicates success back to Camunda Cloud:
notify_Camunda_Cloud:
runs-on: ubuntu-latest
needs: build_and_publish
steps:
- name: Tell Camunda Cloud What's up!
uses: jwulf/[email protected]
with:
client_config: ${{ secrets.ZEEBE_CLIENT_CONFIG }}
operation: publishMessage
message_name: BASE_IMAGE_REBUILT
correlationKey: ${{ github.event.client_payload.buildid }}
variables: '{"test_passed": "false"}'However, execution halts in the GitHub workflow if the task fails. One way to deal with failure is to wrap every step in a GitHub workflow and test for failure, but that is clunky.
Instead, we will use a boundary interrupting timer to detect failure by timing it out. We could publish a message from somewhere else by listening to the repo webhooks, but we want to do this with zero additional infrastructure.
Our timeout task could trigger any notification behavior, but let’s keep it zero-infra and raise an incident in Operate. We can do this by creating a CAMUNDA-HTTP task with an I/O mapping that we know does not exist.
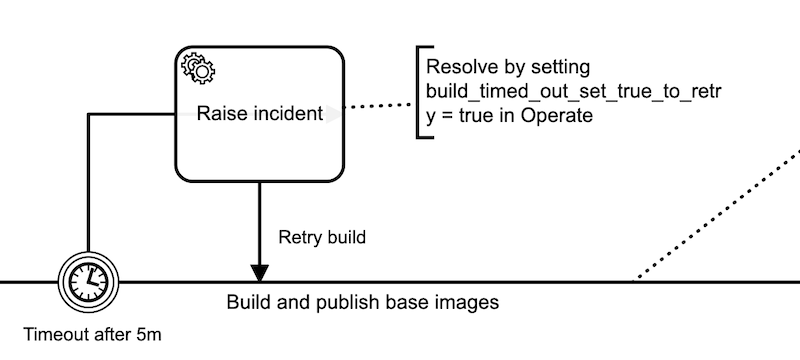
In the I/O mapping we map build_timed_out_set_true_to_retry to dummy. When the token enters this task, it will raise an incident because the variable build_timed_out_set_true_to_retry doesn’t exist. When you fix the issue with the build, you can set this variable to true in Operate and retry.
The I/O mapping for the task maps the build_timed_out_set_true_to_retry variable to dummy on output, so we can reuse this pattern elsewhere – the variable is still unset in the workflow.
This CAMUNDA-HTTP task, when it does run, just does a GET to Google. If that fails, then you have bigger problems.
GitHub Matrix builds
Matrix builds in GitHub workflows allow you to build or test multiple configurations with the same steps. By default the workflow halts on the first failure, but you can specify fail-fast: false to have the build execute all combinations before announcing failure.
name: Publish Docker images
on: [repository_dispatch]
jobs:
build_and_publish:
runs-on: ubuntu-latest
strategy:
fail-fast: false
matrix:
baseimage:
- { image: "oracle/graalvm-ce:19.3.1-java8", tag: graalvm }
- { image: "openjdk:8u171-jdk-alpine3.8", tag: openjdk8 }
minecraft:
- { jar: paper-1.15.2, dockerfile: Dockerfile }
- { jar: paper-1.14.4, dockerfile: Dockerfile }
- { jar: nukkit-1.0, dockerfile: Dockerfile-nukkit }
- { jar: nukkit-2.0, dockerfile: Dockerfile-nukkit }
steps:
- uses: actions/checkout@v2
- name: Publish Docker image to Registry
uses: elgohr/[email protected]
env:
BASEIMAGE: ${{ matrix.baseimage.image }}
MINECRAFT_JAR: ${{ matrix.minecraft.jar }}.jar
with:
name: magikcraft/minecraft
username: ${{ secrets.DOCKER_USERNAME }}
password: ${{ secrets.DOCKER_PASSWORD }}
dockerfile: Dockerfile
tags: ${{ matrix.minecraft.jar }}-${{ matrix.baseimage.tag }}
notify_Camunda_Cloud:
runs-on: ubuntu-latest
needs: build_and_publish
steps:
- name: Tell Camunda Cloud What's up!
uses: jwulf/[email protected]
with:
client_config: ${{ secrets.ZEEBE_CLIENT_CONFIG }}
operation: publishMessage
message_name: BASE_IMAGE_REBUILT
correlationKey: ${{ github.event.client_payload.buildid }}We make the second step (_notify_CamundaCloud) – where we publish the success message to Camunda Cloud, depend on the first step (_build_andpublish) – the one where we publish the Docker images.
We do this by specifying needs: build_and_publish in the second step. This prevents GitHub from parallelizing the tasks and optimistically reporting success back to our workflow in Camunda Cloud.
This ends the first repository’s automation. If this succeeds, then our dependent repository needs to retest, rebuild and publish Docker images, then trigger further dependents.
Multiple causes for an action
Our second repository can be rebuilt in response to two different events:
- A git push to its own code.
- A rebuild of the base images.
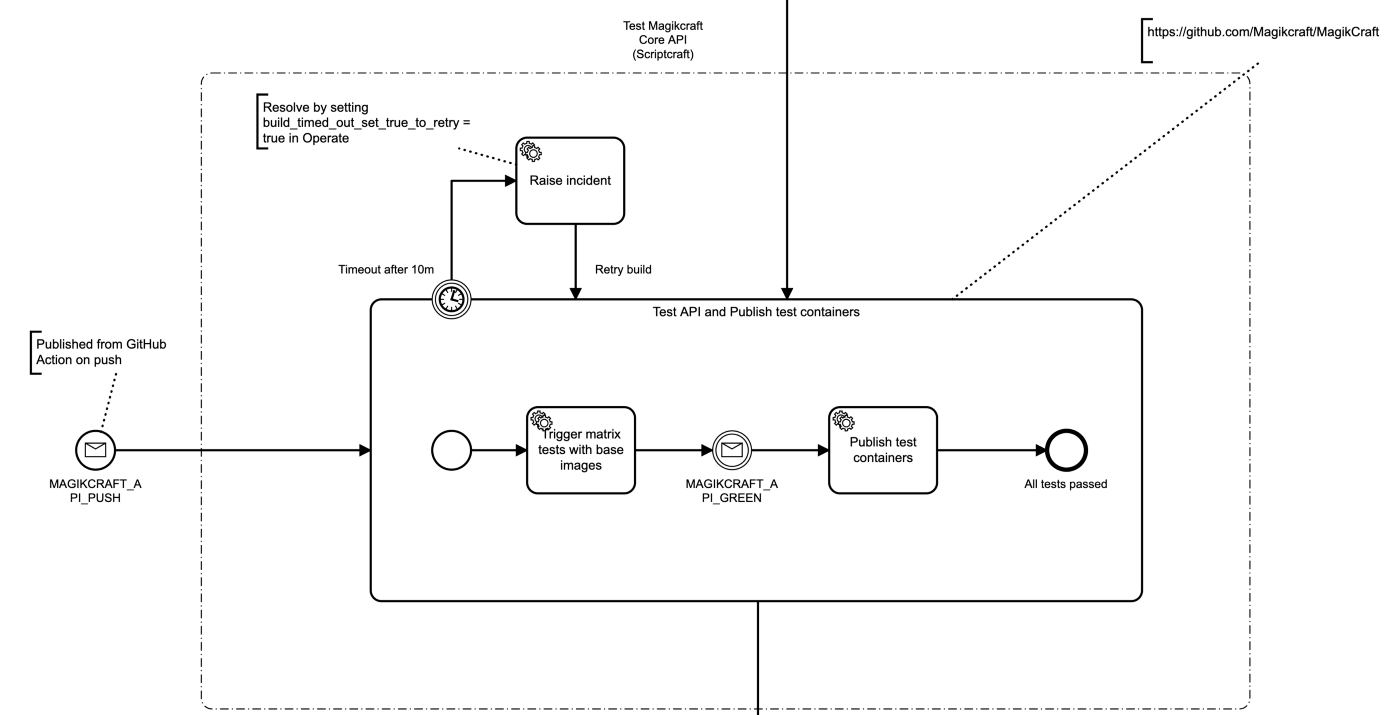
We model this by creating a message start event, and then in the on push workflow in the repository, we publish this message with the metadata that our workflow needs – the templated authorization header to get our GitHub token injected into the HTTP Worker, a unique build ID, and the string constants.
name: Test
on: [push]
jobs:
test:
runs-on: ubuntu-latest
steps:
- name: Get current time
uses: gerred/actions/current-time@master
id: current-time
- name: Kick off workflow
uses: jwulf/[email protected]
with:
client_config: ${{ secrets.ZEEBE_CLIENT_CONFIG }}
operation: publishMessage
message_name: MAGIKCRAFT_API_PUSH
variables: '{"buildid": "${{ github.sha }}-${{ steps.current-time.outputs.time }}", "gitHubToken": "Bearer {{GitHubToken}}", , "TYPE_TEST": "TYPE_TEST", "TYPE_PUBLISH": "TYPE_PUBLISH"}'From that point forward, the workflow in Camunda Cloud is identical, regardless of how we got here.
We use the same timeout pattern to detect failure, and run a matrix test in the next workflow we trigger from the Cloud.
Specializing HTTP Worker payloads
In this sub process we have two distinct GitHub workflows in the same repo that we are triggering from Camunda Cloud using the repository dispatch event.
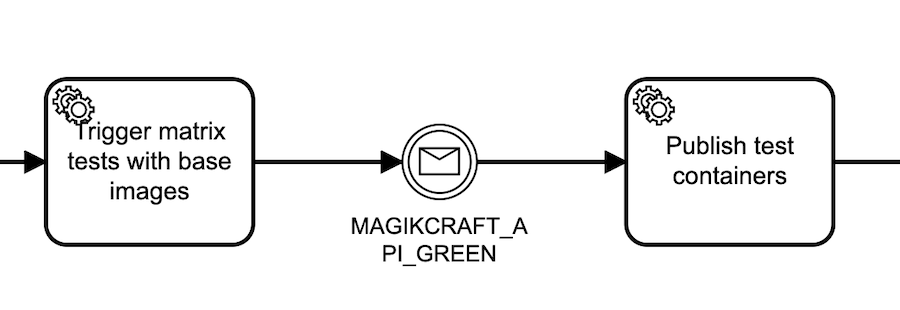
Our tests may fail on the new base images, or due to the new code we just pushed, so we don’t want to publish test containers if it does. So we have a test workflow and a publish workflow.
To get specialized behavior in response to the repository dispatch event, we need to specialize the HTTP Worker task that calls the GitHub API. We do this by mapping one of the string constants from our enum dictionary in the variables to body.event_type in the I/O Mappings for the task:
<bpmn:serviceTask id="Task_0nvbnfg" name="Trigger matrix tests with base images">
<bpmn:extensionElements>
<zeebe:taskDefinition type="CAMUNDA-HTTP" />
<zeebe:ioMapping>
<zeebe:input source="gitHubToken" target="authorization" />
<zeebe:input source="buildid" target="body.client_payload.buildid" />
<zeebe:input source="TYPE_TEST" target="body.event_type" />
<zeebe:input source="test_passed" target="body.client_payload.test_passed" />
</zeebe:ioMapping>
<zeebe:taskHeaders>
<zeebe:header key="method" value="post" />
<zeebe:header key="url" value="https://api.github.com/repos/Magikcraft/MagikCraft/dispatches" />
</zeebe:taskHeaders>
</bpmn:extensionElements>
<bpmn:incoming>SequenceFlow_0weo0p1</bpmn:incoming>
<bpmn:outgoing>SequenceFlow_0a48581</bpmn:outgoing>
</bpmn:serviceTask>Specializing GitHub Workflows
We have two GitHub workflows that are triggered from the repository dispatch event. We can specialize the event_type that we send with the event from Camunda Cloud with the HTTP Worker, now we need to specialize the GitHub workflows.
We can do this with a conditional:
jobs:
test:
if: github.event.action == 'TYPE_TEST'
runs-on: ubuntu-latestThe event_type from the API call appears in the GitHub workflow as github.event.action.
You can debug repository_dispatch events sent to a repository by creating a workflow like this:
name: Debug
on:
- repository_dispatch
jobs:
echo:
runs-on: ubuntu-latest
steps:
- name: Debug
run: echo "${{ toJson(github.event) }}"View the two workflows on GitHub: test and publish.
Ad Infinitum: To Infinity, and Beyond!
The third sub process is essentially the same thing repeated. To run unit tests inside Docker inside a GitHub Action, I took inspiration from this article: GitHub actions running JavaScript unit tests on docker. The Magikcraft and plugin unit tests actually run in JavaScript inside Minecraft inside Docker inside a GitHub Action – now orchestrated by Camunda Cloud.
It’s possible to extend this system further in either direction – for example, the base images are actually built in response to upstream dependencies updating, principally Minecraft server versions. That could be automated and added as a trigger to the whole process.
One thing that became apparent to me is the need to use a standard pattern, and as thin a shim as possible at each layer.
I discovered the idea of passing in string constants to specialize HTTP Worker payloads when I found myself replying to Camunda Cloud with a message that encoded knowledge in the GitHub workflow of where it was in the BPMN process flow – a clear symptom of tight coupling.
The Zeebe Action came about in order to lift a repeated pattern to a first-class concern – I started by creating a light-weight zbctl container and scripting it via BASH in GitHub Actions.
There is more lifting that can be done, and I am sure that as patterns emerge there will be less manual wiring of I/O mappings that will be required to accomplish this integration.
In the meantime, you can accomplish quite a lot with zero-infrastructure.
An important feature of designing systems like this is in their comprehensibility and responsiveness to change – their agility. It is not just “how easy is it to do?” it is “how easy is it to extend and modify the behavior of the resulting system?“
For that, right now, I don’t have an answer. My intuition is that now that the basic components are in place and some patterns have emerged, it will be a flexible system.
Live Stream
Finally, here is a live stream of me working on this.