
In the Zeebe Slack and the Forum, a number of users have been inquiring about initiating a Zeebe workflow via a REST request, and returning the outcome of the workflow in the REST response.
Zeebe workflows are fully decoupled, asynchronous, and have no awaitable outcome. This means there is nothing out-of-the-box right now to do this. We are evaluating demand for this feature in GitHub, both in terms of its eventual shape and its priority.
Let’s look at the problem in more detail, how we can match it with Zeebe’s model, and a few different solutions that you can implement now.
I’m going to be using the TypeScript Zeebe client for code examples in this article, but the concepts are transferable to any of the Zeebe client libraries.
The Problem
We want to initiate a Zeebe Workflow in a REST handler, then send the outcome of the workflow back to the REST client in the REST response. Conceptually, we want to achieve this:
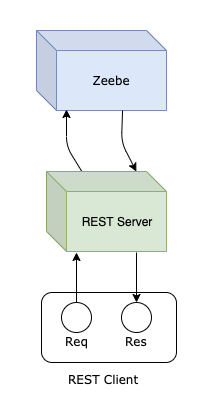
What we need is REST request affinity of a workflow – pinning a workflow outcome to a specific REST request/response context.
We have two things we need to pin. We need to pin:
- A workflow outcome to a specific request/response context.
- If the the REST front-end is scalable, we will need to deal with pinning it to the same REST server.
If we have a singleton front-end REST server, then we can ignore the second problem and implement a class of solution that will not scale across multiple servers by doing the pinning in-memory.
Let’s look at that problem first, because the solution, while not immediately obvious, is straight-forward to implement.
Then, we’ll look at how to scale a solution across multiple REST servers.
Our scenario
Let’s imagine an ecommerce store – the “Todo app” of microservices workflows. Here is our (simplified) “order-fulfilment” workflow, created using the Zeebe Modeler:
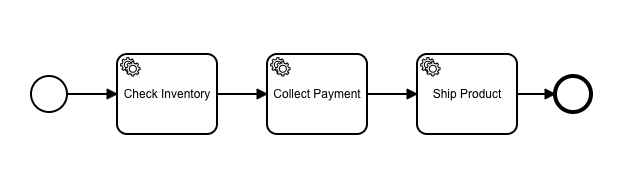
(Sidenote: This scenario, and this “single REST server” solution is what is behind the scenes in my demo in the recent Zeebe webinar.)
Pinning a workflow outcome to a REST session
We can start a Zeebe Workflow easily enough from inside our REST handler. Here is an Express route handler that handles a POST request with a JSON payload. It initiates our “order-fulfilment” workflow, setting the variables that our workflow microservices need:
async function purchaseRouteHandler(req, res) {
const { product, creditcard, name } = req.body;
console.log(`Order for ${name}: ${product} with payment: ${creditcard}`);
const wfi = await zb.createWorkflowInstance("order-fulfilment", {
product,
creditcard,
name
});
console.log(`Started workflow ${wfi.workflowInstanceKey}`)
}We get an awaitable response back from Zeebe for our request to start a workflow, with information such as the unique key identifying this workflow instance.
But how do we await the outcome?
Zeebe’s architectural model is asynchronous, and it is designed around a pub/sub microservices architecture. In August, 2019, there is currently no mechanism for awaiting the outcome of a workflow. In fact, there is not even a first-class concept of a workflow outcome.
Materialising the Workflow Outcome
If there is sufficient demand from users for this feature (awaiting a workflow outcome), then we’ll bake it into the core engine, sooner rather than later. So make some noise in the GitHub issue if you want it.
But, never fear: we can create one using the components that are available to us, right now. To do that, we will create a worker to publish workflow outcomes. Then we can add a “Publish Outcome” task at the end of our workflow, and write a microservice to collect the workflow outcome.
So our workflow now becomes:
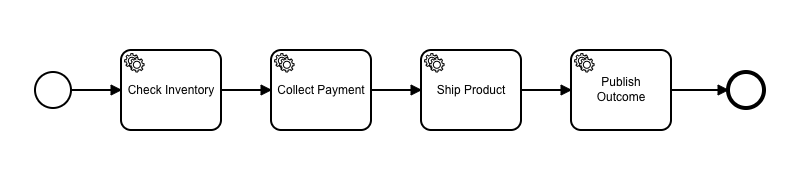
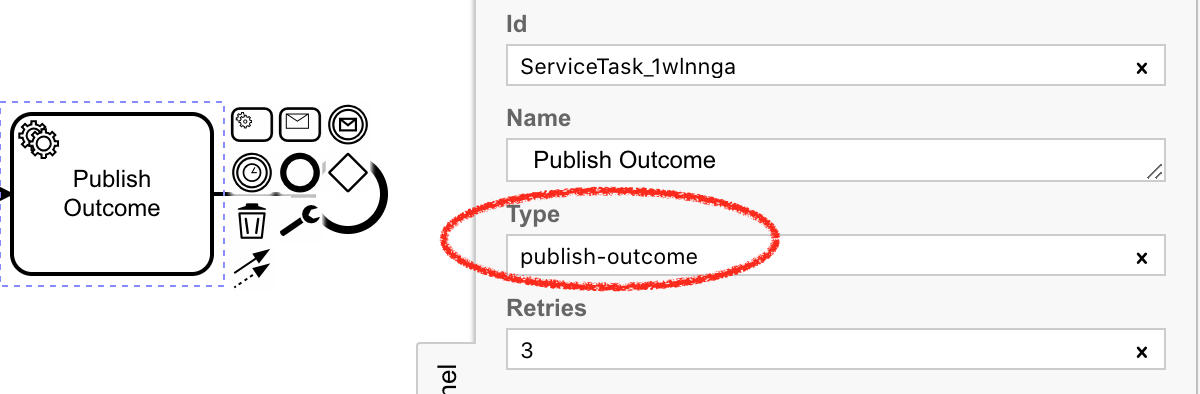
We will make the task-type of the Publish Outcome publish-outcome, and our worker will use this task-type to subscribe to the engine for these tasks:
Workflow Outcome Worker
We will run the worker in the same process as the REST server, so that the REST server has access to the outcome. So in the REST server code, as well as starting an Express server, we will start a Zeebe worker and subscribe it to publish-outcome tasks:
zb.createWorker("outcome-worker", "publish-outcome", (job, complete) => {
const { workflowInstanceKey, variables } = job;
const { operation_success, outcome_message } = variables;
// Pass the variables back to the correct REST session context...
complete.success();
});Getting the Outcome Back into the REST Handler context
There are a number of ways that we can correlate the workflow outcome with the corresponding REST session.
Callback map
We can use an in-memory map of workflow instances key to function closures to get a callback inside the REST handler context:
const callbacks = new Map();
async function purchaseRouteHandler(req, res) {
const { product, creditcard, name } = req.body;
console.log(`Order for ${name}: ${product} with payment: ${creditcard}`);
const wfi = await zb.createWorkflowInstance("order-fulfilment", {
product,
creditcard,
name
});
callbacks.set(wfi.workflowInstanceKey, outcome => res.json(outcome));
}Then in the worker code, we look up the callback in the map, and invoke it:
zb.createWorker("outcome-worker", "publish-outcome", (job, complete) => {
const { workflowInstanceKey, variables } = job;
try {
if (callbacks.has(workflowInstanceKey) {
const cb = callbacks.get(workflowInstanceKey)
cb(outcome);
}
} finally {
callbacks.delete(workflowInstanceKey);
complete.success();
}
});(Sidenote: This is a good use case for the ES6 Map rather than using an object as a dictionary. The frequent addition and removal of keys in an object will either lead to a performance hit over time if we delete the keys, because of V8’s hidden class implementation: see this issue on GitHub and this post on Medium; or a memory leak if we leave them or set them to undefined. See this answer on StackOverflow.)
Event Emitter
With the callback map, you need to either put the worker and the REST handler in an enclosing scope with your callback map, or else export the map. If you have a lot of handlers, then you will probably want to organise your code base with modularity.
Another approach is to use an Event Emitter, and a pub/sub design. You can see this pattern implemented in totality here, but here are the constituent parts. First, the worker:
class WorkflowEmitter extends EventEmitter {}
const workflowEmitter = new WorkflowEmitter();
zb.createWorker("outcome-worker", "publish-outcome", (job, complete) => {
const { workflowInstanceKey } = job;
const outcome = job.variables;
workflowEmitter.emit(workflowInstanceKey, outcome);
complete.success();
});And the Express route handler:
const callbacks: any = {};
async function purchaseRouteHandler(req, res) {
const { product, creditcard, name } = req.body;
console.log(`Order for ${name}: ${product} with payment: ${creditcard}`);
const wfi = await zb.createWorkflowInstance("order-fulfilment", {
product,
creditcard,
name
});
workflowEmitter.once(workflowInstanceKey, outcome => res.send(outcome));
}Event emitters and listeners with dynamic keys make your code harder to reason about. You can no longer reliably “Find all references” on your callback map to trace code execution or refactor. However, this decoupling points us in the direction we need to go to scale this across multiple REST servers. All we need to do here is replace the in-memory event emitter with a network event emitter, and we have something that can scale across processes.
Scaling across multiple REST servers
There are many network pub/sub systems that you could use to solve this: Redis, RabbitMQ, Kafka. If your organization already has one deployed, you just replace the in-memory EventEmitter with that, and suddenly both your outcome worker and your REST front-end are decoupled and independently scalable.
If you don’t have that infrastructure in place, then you can replace the in-memory event emitter with a websocket.
You have a few options about how to structure the system then – and each of them is (mostly) a matter of where you put your complexity.
- With a centralized WebSocket Server that clients and workers subscribe to, in order to distribute outcomes:
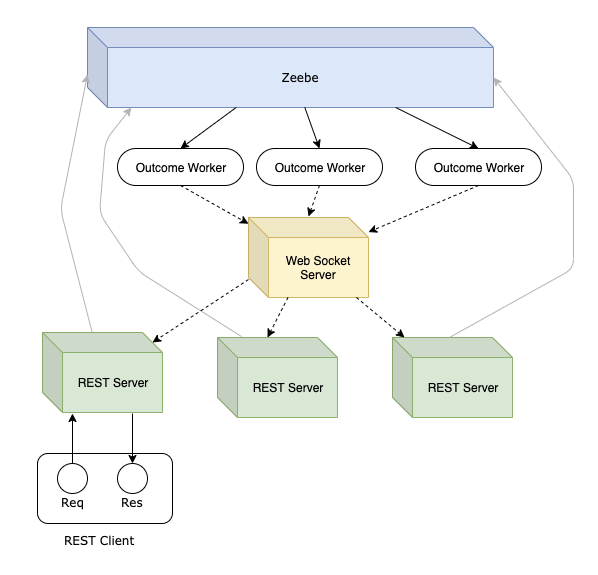
In this architecture you need to stand up another service, which becomes a single point of failure for the entire system if it is not fault-tolerant, or sufficiently scalable.
I’ve written a Proof-of-Concept, non-scalable WebSocket server for this scenario – with an extended zeebe-node-affinity client that encapsulates the programming complexity – leaving you with a new configuration property for the Zeebe client: a WebSocket Server URL; and a new parameter for createWorkflowInstance: a callback for the workflow outcome.
Take a look in the demo directory for instructions on trying it out, if you are interested.
- An embedded websocket server in the ZBClient library, so any outcome worker can call back directly to the interested client, who puts their callback web socket address in the job variables.
This approach means that your Zeebe client implementation must now have a resolvable address that it knows about, and have its network and firewall configured to be contactable by the workers. You no longer have a single point of failure – if the websocket server for a specific outcome is gone, it’s likely that the REST handler context is too (barring some bug in the Web Socket Server implementation). But either way, it is on an individual basis, as the websocket servers to publish outcomes to are distributed between and embedded in the REST servers. You do have to do more configuration and make your clients more complex.
- Some kind of mesh, where workers and clients can publish information about the topology of the network and discover each other.
OK, now you’re about to reimplement Zeebe’s clustering. In this case, you’re better off adding to the GitHub issue asking for it to be built in.
Conclusion
It’s totally possible to do synchronous REST request/response with Zeebe today – and there are a number of ways that you can approach it, depending on how scalable you need it to be, what tools are already in your kit and on your network, and where you want to put the complexity/risk.
If you are building something with Zeebe using synchronous REST req/response, we’d love to hear from you! We’re keenly interested in understanding users’ scenarios to see how we best support this, and when, in the core engine. Reach out on Slack, in the Forum, or by emailing [email protected].
