
The upcoming 0.21 release of Zeebe includes a feature many users have been asking for: long-polling for workers. And make sure you stay tuned to the end to find out what a massive deal it is.
Zeebe is a radical re-imagining of the workflow engine for the modern world: it uses event sourcing to interpret workflows over immutable streams. In the Zeebe model, workers are de-coupled from the broker. Conceptually, workers “subscribe” to task types on the broker to service. In terms of actual implementation, workers poll the broker for the task type they service. This allows the broker to have no stateful knowledge about workers.
The Problem With Polling
Every request to the broker for work from a worker – an ActivateJobs request – is an “event” in the stream that Zeebe processes; several, in fact. Each ActivateJobs request from a worker causes an ACTIVATE command record to be added to the broker record stream. This record is processed by the broker’s stream processor, which adds an ACTIVATED event record to the stream when the request has been serviced.
This means that workers cause load on the broker even when there is no work. One worker for a single task polling at 100ms causes twenty records per second to be added to the broker event log.
Zeebe is designed to be fast and scalable. However, with short polling you could not achieve both. Frequent polling gives responsive task servicing, but impacts the broker’s performance.
In releases of Zeebe prior to 0.21, you had two options:
- If you wanted low-latency of task execution, you would have workers poll the brokers frequently: many client libs (Java, Go, and Node, for example) would poll the broker every 100ms by default (10 times per second per task type). This gives very fast execution of tasks when they appear.
- If you wanted to reduce the load on the broker, you would configure the client library to poll at longer intervals, and pay a price in responsiveness to work when it appeared.
The Magnitude of the Problem
To get an idea of the impact, I measured CPU utilization on a pre-release version of the 0.21 broker (change the image tag to SNAPSHOT in the broker-only profile from zeebe-docker-compose – and be sure to docker pull camunda/zeebe:SNAPSHOT), using a long-polling branch of the Node.js client, and averaging the CPU utilization with docker stats over 15 seconds.
Here is the profiling code:
import stats from "docker-stats";
import through from "through2";
import { v4 as uuid } from "uuid";
// Note: requires 0.21.0 of the zeebe-node lib
// https://github.com/creditsenseau/zeebe-client-node-js/pull/65
import { ZBClient } from "zeebe-node";
const readline = require("readline");
readline.emitKeypressEvents(process.stdin);
process.stdin.setRawMode!(true);
// Emit average CPU usage every 15 seconds
stats({
statsinterval: 15,
matchByName: /zeebe_broker/
})
.pipe(
through.obj(function(chunk, enc, cb) {
const cpu = chunk.stats.cpu_stats.cpu_usage.cpu_percent;
this.push(
`Fast: ${fast} || Slow: ${slow} || Long: ${long} || CPU: ${cpu}`
);
this.push("n");
cb();
})
)
.pipe(process.stdout);
let fast = 0;
let long = 0;
let slow = 0;
let zbcLong = new ZBClient("localhost", {
longPoll: 300000
});
const zbcShort = new ZBClient("localhost");
const unusedHandler = (job, complete) => console.log(job);
const createLongpollWorker = currentZbcLong =>
currentZbcLong.createWorker(uuid(), "nonexistent-task-type", unusedHandler);
const createFastPollWorker = () =>
zbcShort.createWorker(uuid(), "nonexistent-task-type", unusedHandler);
const createSlowPollWorker = () =>
zbcShort.createWorker(uuid(), "nonexistent-task-type", unusedHandler, {
pollInterval: 1000
});
console.log("Start another (f)astpoll worker, (s)lowpoll or (l)ongpoll worker");
process.stdin.on("keypress", function(ch, key) {
if (key.name == "f") {
createFastPollWorker();
fast++;
}
if (key.name == "s") {
createSlowPollWorker();
slow++;
}
if (key.name == "l") {
createLongpollWorker(zbcLong);
// Too many long polling workers on a single gRPC connection is a problem
if (long++ % 40 == 0) {
zbcLong = new ZBClient("localhost", {
longPoll: 300000
});
}
}
if (key && key.ctrl && key.name == "c") {
process.exit();
}
console.log(`Fast: ${fast} || Slow: ${slow} || Long: ${long}`);
});Here is the CPU utilisation with workers polling at 100ms:
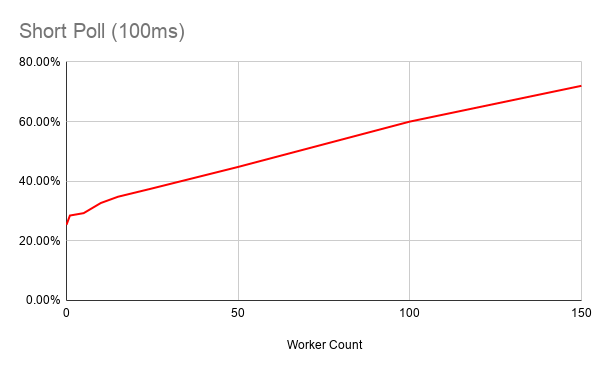
You can see that it uses significant resources – and bear in mind that this is the CPU usage for a broker that is not running any workflows.
So when you have actual work to do, fast-polling workers for tasks that currently have no work are chewing up resources and getting in the way of the real business of the broker.
As you increase workers to scale up, you also scale up the ActivateJobs requests. It’s like turning up a recording with background hiss to be able to better hear the music. Now you are listening to the same hiss, at a louder volume. That is not scalable.
Dialling the worker polling interval back to 1 second significantly reduces the load:
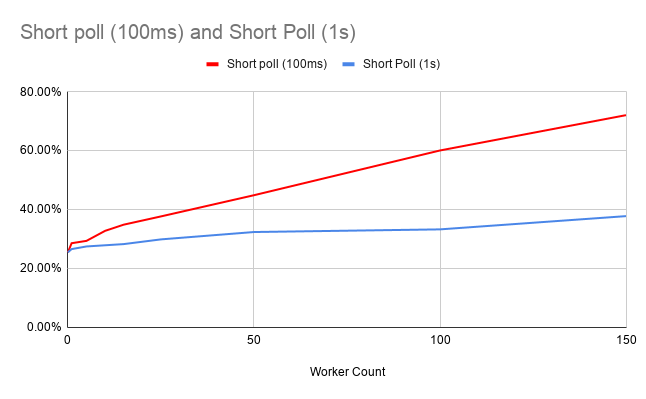
This looks more scalable. You’ve got the same number of workers, and if the work they do takes more than one second to complete, then this may be sufficient.
If, however, you are running complex workflows that you want to complete in milliseconds, this is not going to work for you, because the system has a potential latency of count(tasks) seconds, because of the polling interval.
Fast or scalable – with fast polling, choose one.
Why can’t we have both? A low noise-floor and low-latency?
Well, now we do: long-polling.
How Long Polling Works
Zeebe task workers communicate with the broker cluster over gRPC, a binary protocol over HTTP/2. This supports long polling: opening a request, and leaving it open for an arbitrary amount of time, or until the server responds.
Rather than receiving back a response from the Zeebe gRPC Gateway saying “no work for you to do right now“, with long polling the server keeps the request open until work appears.
In 0.21.0-alpha1, the broker terminates the poll after 10 seconds as a hard limit. With SNAPSHOT, though, the client tells the gateway how long the poll should last.
While implementing long-polling support in the Node.js client, I ran the load test against SNAPSHOT, with the long poll timeout set to 30 seconds. Here is what the CPU load looks like, compared with the 100ms and 1s fast poll:
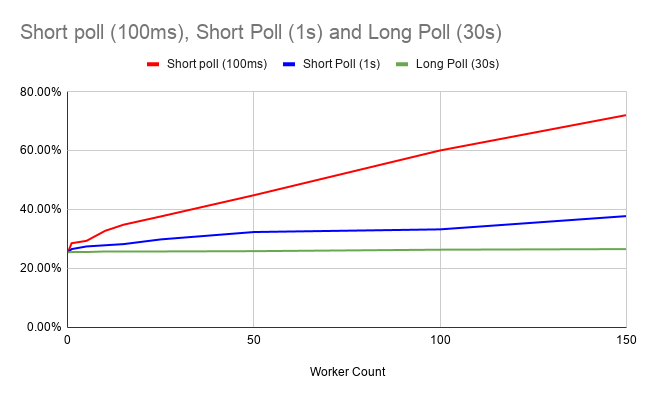
As you can see, the long-polling worker has very little impact on the broker. It is extremely scalable. But is it fast?
The zeebe-ecommerce-demo includes a “Cyber Monday” mode that spawns and services 1000 workflows with five task types. It’s a useful rough-and-ready test, so I tried it with all three. Here are the results:
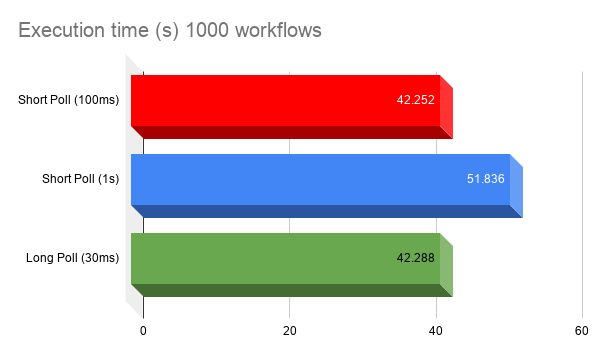
As you can see: switching between 100ms and 1s short polling interval causes a 21% increase in execution time (42.2 vs 51.8 seconds), due to latency . However, using 30s long-polling workers results in the same performance as 100ms polling workers, but – as we established earlier – using a fraction of the broker resources.
Note that this is not a measure of Zeebe’s speed – it is a comparison of the relative performance of different worker polling setups on the same workflow. Zeebe can start and complete more workflows per second than this. These workflows are started at the rate of one every 40ms, and one of the task workers has a two-second delay, to simulate a REST request to an external API.
History of Long Polling Workers in Zeebe
This is actually the second time that long-polling workers has been implemented in Zeebe.
Thorben Lindhauer first implemented it back in 2016. At that time, the Zeebe dev team hadn’t implemented the stream processing model that Zeebe now uses to achieve massive horizontal scalability. When the refactor to stream processing happened, long polling was removed. Bernd Rücker floated that long-polling was needed for responsiveness. As a workaround, Sebastian Menski changed the default short poll in the client libs to 100ms. This solved the responsiveness issue in the short term, but at the cost of the load issue. Users encountered this, and raised it as an issue in the Zeebe Forum.
The engineering team and product management triaged it, and prioritized it for this quarter.
Two take-aways from this:
- Watching the Zeebe GitHub – both issues and pull requests – is a great way to stay up with what is coming down the pipe (as well as reading the Zeebe blog).
- Creating and commenting on GitHub issues and in the Zeebe Forum is a powerful opportunity to influence the future direction of Zeebe.
Summary
Long-polling for workers is a great feature coming in Zeebe 0.21. It increases Zeebe’s performance and scalability. For the Go and Java clients, long polling will be the default behavior. For Node, you will need to specify long polling.
It is worth understanding long polling, and the motivation behind it, ahead of its arrival.
Further resources
- Change to gRPC Protocol to support long polling in Zeebe 0.21
- Long Polling Documentation PR
- Performance drop in broker after long polling was added (Resolved)
- Configure Long Polling timeout in Java client
- Configure Long Polling timeout in Go client and zbctl
- Long Polling support in the JavaScript client