
Zeebe can be used to orchestrate data-processing pipelines, such as image processing or machine learning.
As discussed in Google’s Site Reliability Engineering book, one issue with data-processing pipelines is responding in a timely fashion to increased business demands.
Zeebe is a stateful workflow engine, and state doesn’t scale horizontally – but Zeebe does. So you want to design your pipelines in a way that encapsulates and isolates state and allows you to scale up workers in the parts where you can parallelize work.
One computational solution pattern that enables this is Map/Reduce. In this post we’ll look at how you can use Zeebe to build Map/Reduce pipelines.
This is not meant to be a production-ready solution, but just to get you thinking about possible approaches using the primitives available to you in Zeebe.
A working example of this code is available on GitHub. The ideas in this article are illustrated using the TypeScript client library for Zeebe, but they are equally applicable in Java, Go, C#, Python, or Ruby.
I’ve made it sufficiently generic that it is reusable, and in fact composable. By writing strongly-typed interfaces and a class to manage some of the coordination, you can achieve a significant level of separation of concerns between the orchestration in Zeebe and its (re)use by developers.
Parallelizing Work
A intuitive initial attempt to parallelize work might involve sub-processes in a single workflow:
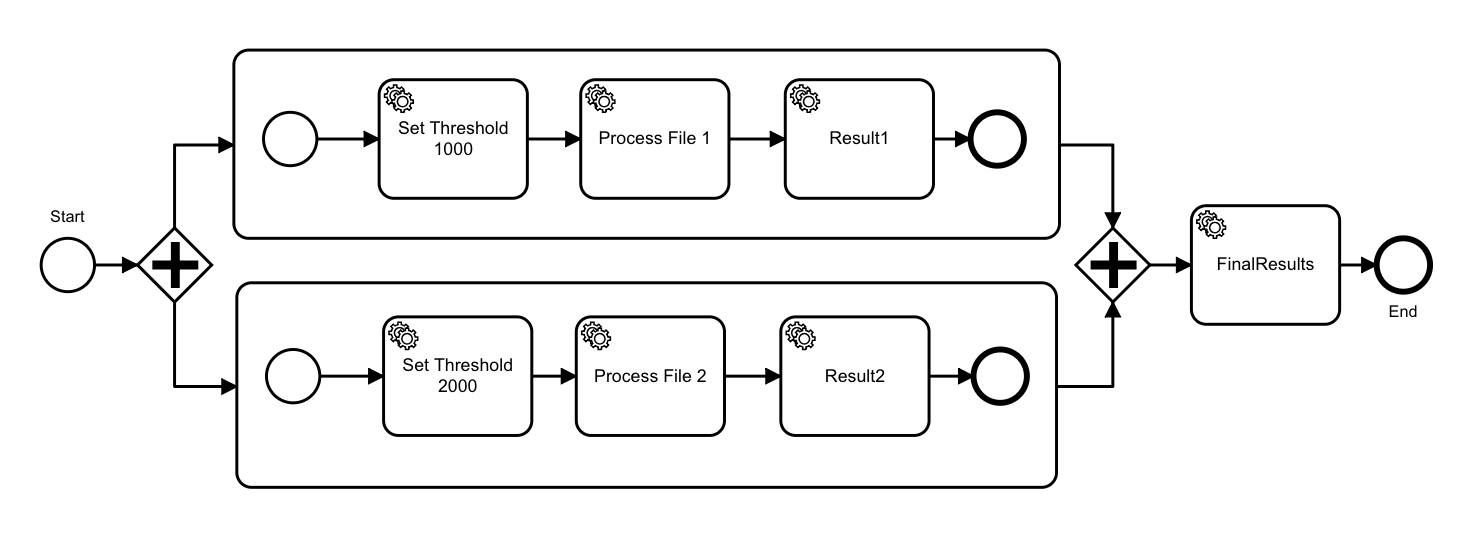
However, in order to parallelize and scale the workers, we need to split the workflows. This is because a workflow is stateful – and stateful computation doesn’t scale well. A workflow’s state is stored in the workflow variables, and while you can achieve some isolation through sub-processes and locally-scoped variables, you will be conflating concerns by trying to handle that in a single workflow. Parallel sub-processes in the same workflow mutate the same variables in the global scope.
Also, while this approach has the advantage that it is very explicit, it does not DRY the map/reduce functionality out from your pipelines’ specific transformations. That means that for every transformation step in each pipeline you would be explicitly re-wiring the map/reduce flow.
Domain-driven design
I’m big on domain-driven design, and if the domain is microservice orchestration, then you could view map/reduce functionality as a bounded context.
Most programming languages provide some kind of map functionality for collections. As a developer, you don’t care so much how it is implemented – just that it is there, and that you can use it.
And when you implement some optimization in the map functionality, everything that uses it benefits – rather than having to go through every single pipeline diagram and update it.
DRY-ing out Map/Reduce
You will get more mileage if you map your solution to the split-apply-combine boundaries of concern implemented by the Map/Reduce pattern.
So you have one workflow that is concerned with the shared state – that is: splitting the input, and combining and producing the output; and a separate workflow that implements the apply part of the pattern – the part that can be scaled independently by adding more worker resources.
Split/Combine Workflow
Here is the main workflow that both splits the input into distinct, independently-processable units; and combines the results of workers to produce the final output:
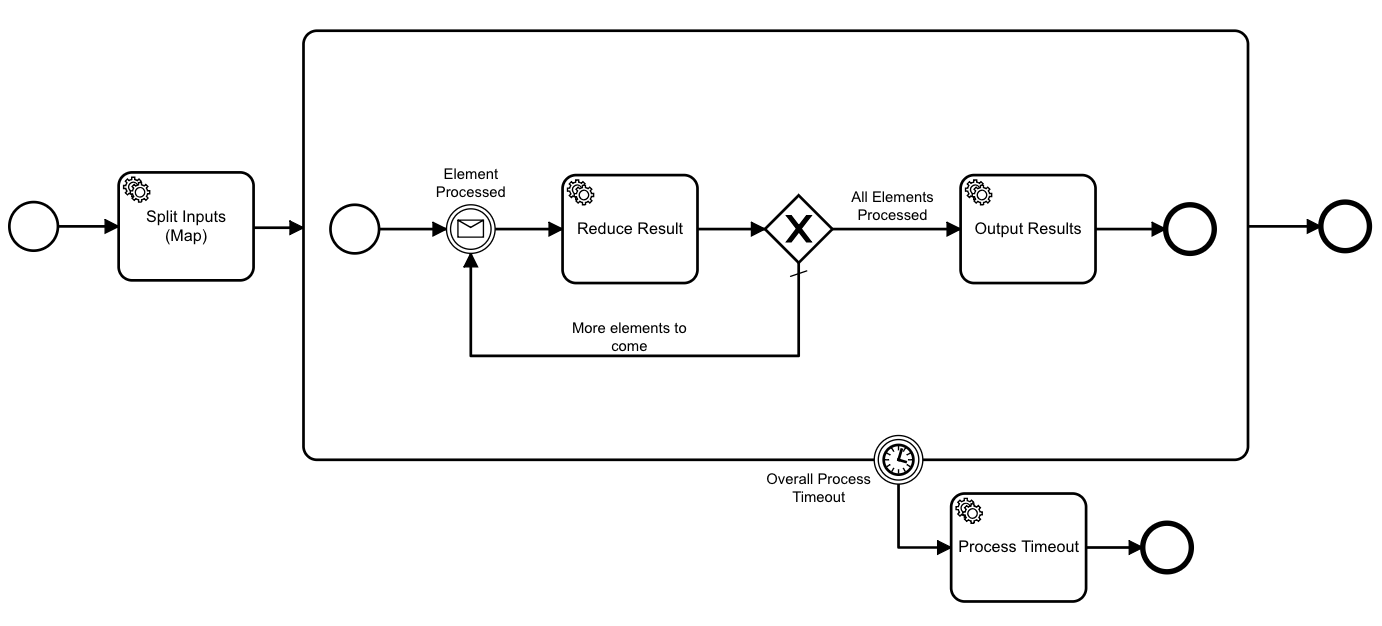
The “Split Input” task takes both the input elements and the id of the workflow that will be invoked to transform each of them.
You can think of the input signature as:
interface MapReduceInput {
elements: any[];
mapFunctionWorkflowId: string;
}
[/ highlight]
_Side note: it's actually a little more complex than this, because we pass in a correlation key and also configuration to message the results back._
By taking a "mapFunctionWorkflowId" as an input, the implementation is sufficiently generic that it can be used to Map/Reduce _any workflow_ over _any set of inputs_. You are responsible for ensuring that the map function workflow worker can handle the type of the input elements - there is no compiler-enforced type-safety in the coupling between workers and tasks, or between workflows.
You can write classes around these interfaces to make sure they are adhered to at the application-programming level. In the [example code on GitHub](https://github.com/jwulf/zeebe-map-reduce), I've done exactly that - providing a type-safe application-level API.
## The Way This Works
The "Split Input" task worker will iterate over the elements in the `elements` variables, and for each one create an instance of the `mapFunctionWorkflowId`, passing in the element. It also passes in a unique correlation key. This is used by the map function worker to message the result of its processing to the main workflow (via [message correlation](https://docs.zeebe.io/reference/message-correlation.html)) where it is _combined_ - reduced with the current result set.
Here is code implementing the "Split Inputs" task worker:
``` typescript
zbc.createWorker<MapReduceInput>(uuid(), "split-inputs", (job, complete) => {
const { elements = [], mapFunctionWorkflowId } = job.variables;
const correlationKey = job.variables;
const tasks = elements.map(element =>
this.zbc.createWorkflowInstance(mapFunctionWorkflowId, {
element,
correlationKey
})
);
console.log(`Spawned ${tasks.length} workflow instances`); // @DEBUG
complete();
});Note: we create the “correlationKey” at the application level and pass it in via a variable to avoid workers returning results while we are still creating tasks. The messages could be buffered until we update the value of the correlationKey via complete({correlationKey}), however we just avoid it altogether by making sure it is set ahead of time.
After the “Split Input” task creates workflow instances for each of the elements, the token moves into the reducer subprocess, and halts at the “Element processed” message catch.
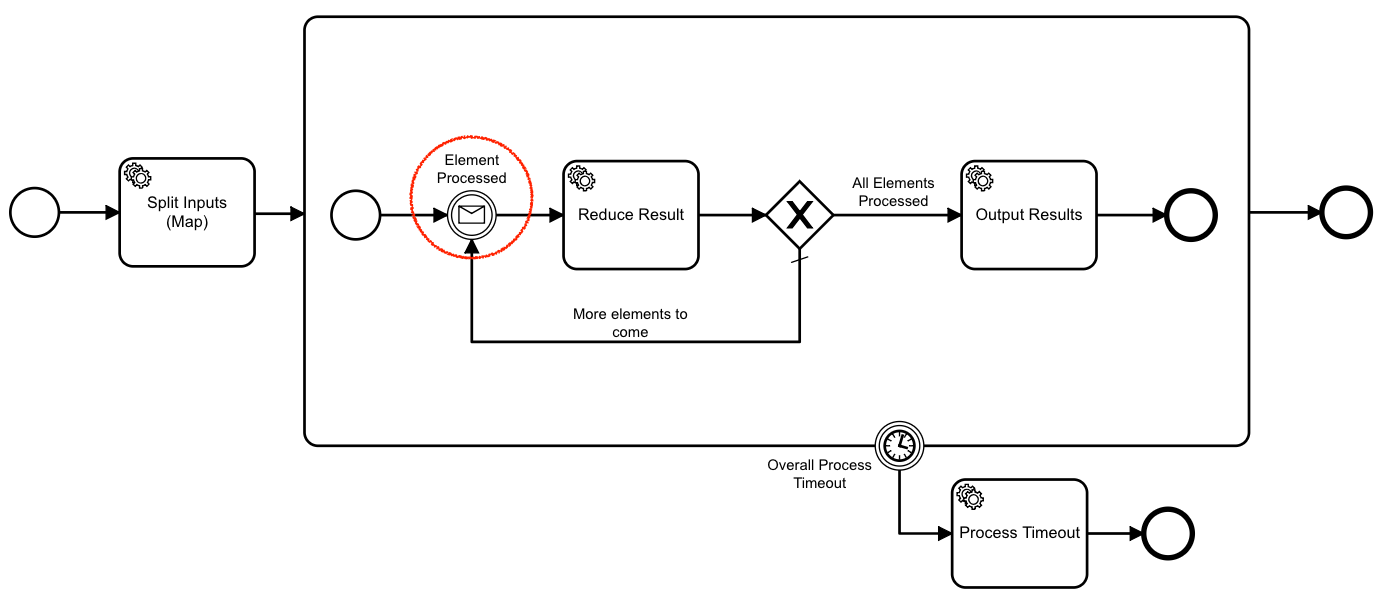
It waits here until a worker messages back a result. When it receives a result, it reduces that result with the result set, then checks to see if all results are in. If they are, it proceeds to the output task. If not, it goes back to wait for the next result.
Here is the code for the reducer task worker:
zbc.createWorker<MapReduceOutput>(uuid(), "collect", (job, complete) => {
const { accumulator, element, elements } = job.variables;
accumulator.push(element);
const done = accumulator.length === elements.length;
console.log(`Collected: ${accumulator.length}/${elements.length}`); // @DEBUG
complete({
accumulator,
done
});
});The reducer subprocess has a boundary timer event. If this fires before the subprocess completes, the token moves to the “Process time out” event. This is the way to deal with something going wrong – for example: dependent workflows failing, and never returning a result.
Note that with a naive implementation, the result set is not guaranteed to be ordered the same as the input set. The ordering of the result set will reflect the order in which the broker received results from workers. Network conditions, resources on workers, and the complexity of computation will affect this.
The Apply Workflow
The apply workflow is simple. In our example, it has a single task:
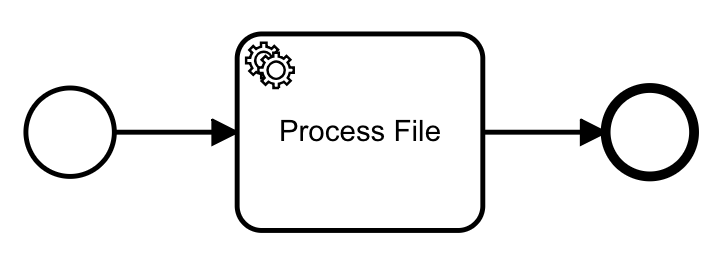
By convention, the apply workflow has the interface:
interface ZeebeMapFunctionInput {
element: any;
correlationKey: string;
}
interface ZeebeMapFunctionResponse {
element: any;
}The apply workflow performs the transformation of the “element” variable, and messages the result back to the main workflow, using the value of the “correlationKey” variable it received:
zbc.publishMessage<ZeebeMapFunctionResponse>({
name: "collect-result",
correlationKey,
timeToLive: 30000,
messageId: uuid(),
variables: {
element: currentValue
}
});The “correlationKey” causes the result message to be correlated with the specific workflow instance that spawned it, and that workflow instance collects and reduces the state.
What’s Missing / Of Note
There are a few things to note about this implementation:
- It’s all or nothing – if any one of the element transform workflows fail, the process will time out. You could handle this in the time out handler by returning a partial state with an error message.
- Results are out-of-order with respect to the input – you need to handle the ordering, because they are accumulated based on the order of processing completion.
- Payload size has a limit – You cannot push in megabytes of data. For large input data, you will need to push in an array of references, like AWS S3 URLs, and writing the task workers to retrieve the actual data.
Have an Idea for an Alternative Approach?
There is always more than one way to peel an orange. If you’ve come up with another approach, or a variation on this one, I’d love to hear about it!
You can find me on the Zeebe Slack, or in the Zeebe Forums.
I look forward to hearing about the awesome things you are creating with Zeebe!
