
Bernd Rücker is a co-founder and developer advocate at Camunda.
With Zeebe.io we provide a horizontally scalable workflow engine completely open source. We face a lot of customer scenarios where Zeebe needs to be connected to Apache Kafka (or the Confluent Platform).
I’m currently working on an article about the various use cases here, ranging from process-based monitoring to stateful orchestration. I will link it here when it’s ready, and until then, my talk from Kafka Summit San Francisco might be helpful for you.
A relatively easy but clean way to integrate with Kafka is Kafka Connect. For a proof-of-concept, I implemented a prototypical connector:
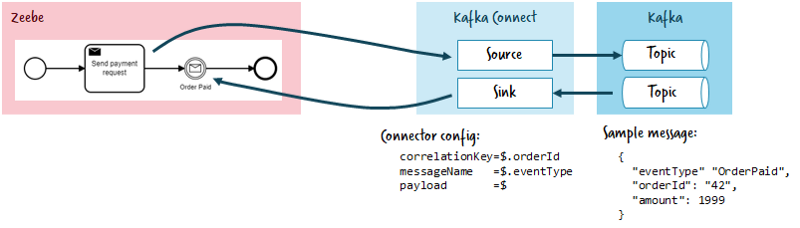
Features:
- Correlate messages from a Kafka topic with Zeebe workflows. This uses the Zeebe Message Correlation features. So, for example, if no matching workflow instance is found, the message is buffered for its time-to-live (TTL) and then discarded. You could simply ingest all messages from a Kafka topic and check if they correlate to a workflow instance in Zeebe.
- Send messages from a workflow in Zeebe to a Kafka topic.
How to Use the Connector
You can find the source code here.
- Build via
mvn package - Put the resulting UBER jar into
KAFKA_HOME/plugins - Run Kafka Connect using the Connector pointing to the property files listed below:
connect-standalone connect-standalone.properties zeebe-sink.properties zeebe-source.properties
An example can be found in the flowing-retail sample application.
Sink (Kafka => Zeebe)
The sink will forward all records on a Kafka topic to Zeebe:
name=ZeebeSinkConnector
connector.class=...ZeebeSinkConnector
correlationJsonPath=$.orderId
messageNameJsonPath=$.eventType
zeebeBrokerAddress=localhost:26500
topics=flowing-retailIn a workflow model, you can wait for certain events by name (extracted from the payload by messageNameJsonPath):
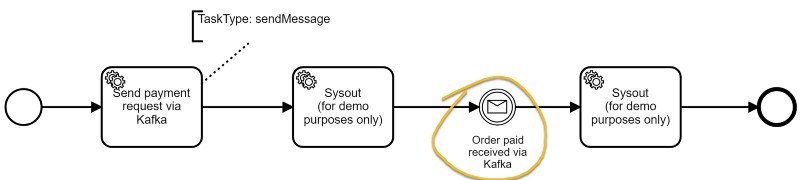
Source (Zeebe => Kafka)
The source can send records to Kafka if a workflow instance flows through a certain activity:
name=ZeebeSourceConnector
connector.class=...ZeebeSourceConnector
zeebeBrokerAddress=localhost:26500
topics=flowing-retailIn a workflow, you can then add a Service Task with the task type “sendMessage” which will create a record on the Kafka topic configured:
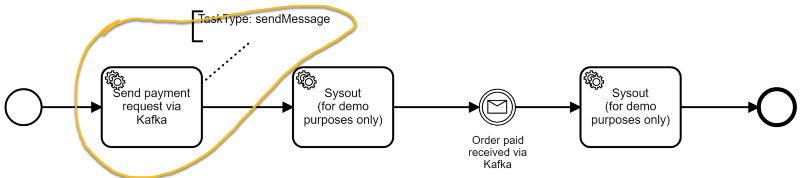
Understand the Source Code and Basic Design Decisions
The source code is available on GitHub.
Sink
Writing a sink is relatively straightforward once you’ve written all the boilerplate code to configure your connector.
One assumption for the prototype is that all messages contain plain JSON without a schema. The easiest handling is if we get that JSON as String, so the connector must be configured to use the StringConverter. For now, the connector cannot process anything else (like e.g. Avro messages) but this would be easy to extend.
The main idea is that you get all messages (“records” in Kafka speak), convert the payload to a JSON string, extract correlation information via JsonPath and hand over the message to Zeebe.
public void put(final Collection<SinkRecord> records) {
for (SinkRecord record : records) {
String payload = (String) record.value();
DocumentContext jsonPathCtx = JsonPath.parse(payload);
String correlationKey = jsonPathCtx.read(correlationKeyJsonPath);
String messageName = jsonPathCtx.read(messageNameJsonPath);
// message id it used for idempotency - messages with same ID will not be processed twice by Zeebe
String messageId = record.kafkaPartition() + ":" + record.kafkaOffset();
zeebe.workflowClient().newPublishMessageCommand() //
.messageName(messageName) //
.correlationKey(correlationKey) //
.messageId(messageId) //
.payload(payload) //
.send().join();
}
}One important detail is the message id for Zeebe, which is constructed out of the Kafka Partition and Offset. This makes the id unique for every record in the system. Zeebe is capable of idempotent message sending.
This means that whenever you resend a message to Zeebe, it will not be processed again. This makes me very relaxed in the connector, as I do not have to bother with consistency: Kafka Connect assures at least once delivery (meaning, whenever there is an exception or crash during the put method, the record will be processed later on again) and Zeebe can deal with duplicate messages.
Source
Kafka Connect requires polling new data to ingest into Kafka. Now Zeebe itself is build on modern paradigms and provides a streaming API. It is not possible (yet) to poll for tasks.
So I opened a Zeebe subscription to collect all Zeebe jobs that needs to be done in a in-memory queue.
private ConcurrentLinkedQueue<JobEvent> collectedJobs = new ConcurrentLinkedQueue<>();
public void start(final Map<String, String> props) {
zeebe = ZeebeClient.newClient();
// subscribe to Zeebe to collect new messages to be sent
subscription = zeebe.jobClient().newWorker() //
.jobType("sendMessage") //
.handler(new JobHandler() {
public void handle(JobClient jobClient, JobEvent jobEvent) {
collectedJobs.add(jobEvent);
}
}) //
.name("KafkaConnector") //
.timeout(Duration.ofSeconds(5)) //
.open();
}This queue is then worked on by Kafka Connect and the job is completed right after. Every job is locked for a short timeout (5 seconds at the moment). After Kafka Connect has created the record, it calls a commit method which then completes the task in Zeebe. If the job does not get processed because of a crash, it will be re-executed automatically, so we apply at-least-once semantics for the creation of records.
public void commitRecord(SourceRecord record) throws InterruptedException {
Long jobKey = jobKeyForRecord.remove(record);
zeebe.jobClient() //
.newCompleteCommand(jobKey) //
.send().join();
}The record gets a payload with a JSON string of the payload contained in the Zeebe process, which is configurable via Input Mappings of the workflow definition:
public List<SourceRecord> poll() {
List<SourceRecord> records = new LinkedList<>();
JobEvent jobEvent = null;
while ((jobEvent = collectedJobs.poll()) != null) {
for (String topic : kafkaTopics) {
final SourceRecord record = new SourceRecord(null, null, topic,
Schema.BYTES_SCHEMA, //
jobEvent.getPayload().getBytes(Charset.forName("UTF-8")));
records.add(record);
}
}
return records;
}That’s it. Have fun.
Status and Feedback
This connector is just a proof of concept and the code might serve as a starting point for your own project. We regularly discuss having a proper connector as part of the Zeebe project. If this would help you don’t hesitate to contact me and describe your use case at hand — this might help us to prioritize accordingly.
Bernd Ruecker is co-founder and developer advocate at Camunda. He is passionate about developer-friendly workflow automation technology. Follow him on Twitter or check out his homepage. As always, he loves getting your feedback. Send him an email!
