
-
Zeebe 0.12 supports message events, making it easy to use Zeebe as part of an event-driven architecture; workflow instances can to respond to events published by external systems.
- And Zeebe handles all of the heavy lifting related to correlating a message to a workflow instance: buffering incoming messages, opening a subscription to receive messages that match with active workflow instances, and correlating a message (when one exists) to a workflow instance that has arrived at a message event.
Last month’s Zeebe 0.12 release introduced support for two BPMN elements that are core to Zeebe’s ability to operate in an event-driven architecture: the intermediate message catch event and the receive task. These elements make it possible for workflow instances to react to messages published by an external system, progressing to the next step in the workflow only after a message with a matching message name and correlation key has been correlated to an instance.
Zeebe was designed to operate at large scale. It’s easy to imagine a scenario where tens or hundreds of thousands of active workflow instances are waiting for incoming messages, and each message can be “correlated” to the correct workflow instance via a shared correlation key. This matching of messages to workflow instances must happen quickly and accurately–ideally, without any heavy lifting required by the user.
And so 0.12 also includes a range of new features to enable the correlation of messages to workflow instances in a partitioned system. Later in the post, we’ll touch on how message correlation in Zeebe works “under the hood”.
We’ll also talk through a sample use case and go into more detail on both the “why” behind messages and message correlation in orchestration, and we’ll also give an intro on how to work with messages in Zeebe. And throughout the post, we’ll highlight a few ways that Zeebe works with messages differently than Camunda BPM.
Messages in microservices orchestration: communicating with a workflow instance from the outside world
In BPMN, the intermediate message catch event and receive task are the symbols that enable a workflow instance to react to messages published by an external system.
From a business perspective, a message event or receive task might be necessary when a workflow instance should proceed to the next step in a model only after a message from an external system is received. Or when a workflow instance needs to receive data from an external system so that the workflow instance payload can be updated. Or, of course, when both of these things need to happen!
Let’s discuss an example. We’ll use our standard e-commerce order process as a starting point.

Imagine that you’re the person responsible for the payments microservice that carries out the first step in the order. You’ve noticed a recurring issue with payments: sometimes, customers try to pay for an order with a credit card that’s saved in their account but the card is declined.
This could happen for a number of reasons. Maybe the card is over its spending limit, or maybe the card details were input incorrectly by the customer during account setup.
When a card is declined, your company’s website prompts the user to update the payment details in their account. But the account microservice where the card details are stored is owned by a different team within the company, and our payments service doesn’t know when to try to reprocess a payment–unless the account service can publish a message notifying when payment details have been updated. As it currently stands, though, active orders are getting “stuck” at the payment processing step when a customer’s card is declined.
So, initially, the logic within our payments service is very rudimentary. We simply try to process a payment, and it either succeeds or it doesn’t. If we were to model it in BPMN, it would look something like this.
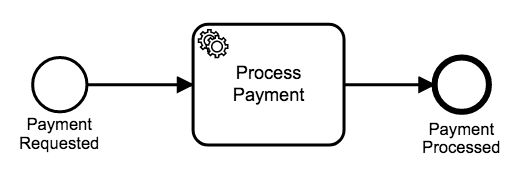
To make our payments process a bit more resilient, we decide to include Zeebe in our service and to deploy the following workflow model.
If we process a payment successfully, we simply progress to the end event, same as we did in our original model. If a payment is declined, however, we wait for a message to be published by the account microservice confirming that the customer’s payment method has been updated successfully.
When that message comes in, we try to reprocess the payment.
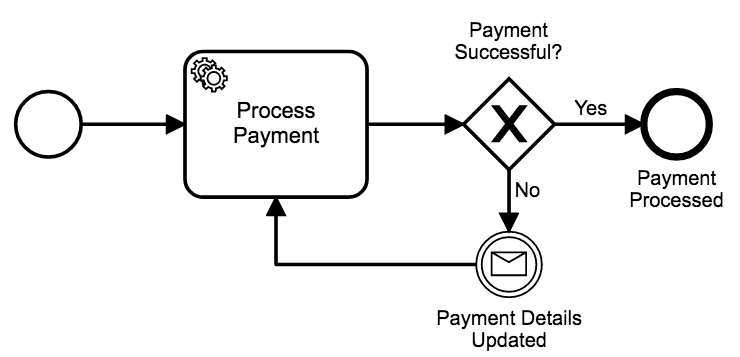
If users decide not to update their payment details after being prompted to do so, it’s true that some workflow instances will still be held up at the Payment Details Updated message event.
But when users do update their details, our service can finish the work that it’s responsible for, and we can move forward with the original order. Additionally, we have a lot more visibility into why some instances are stuck than we did in our original approach, and therefore, we have more options for trying to solve the problem.
For example, we might choose to send a courtesy email to customers whose orders are stuck on this step, reminding them to update their payment details.
How exactly does message correlation work under the hood?
We touch on internals of this feature in the Message Correlation section in the Zeebe docs, and we’re going to walk through it in a bit more detail here, too. In this section, we’ll also highlight how message behavior in Zeebe is different from what you might be used to if you’ve worked with message events in Camunda BPM.
Whenever a message is published to Zeebe, the message is stored in a “buffer” until it can be correlated with a workflow instance. You can visualize it like so:
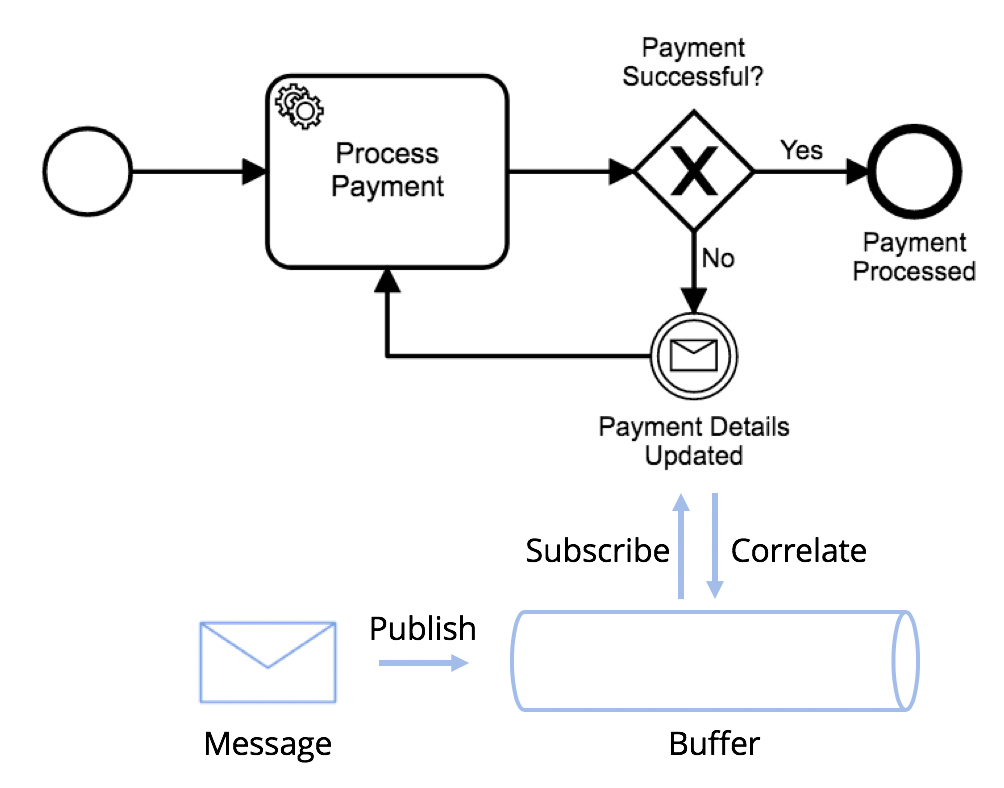
If you’re familiar with how messages work in Camunda BPM, you might have noticed something unexpected in that previous paragraph: that messages are “buffered” and can be stored for an arbitrary period of time, even if there’s no active workflow instance with a token at a message event that’s ready to receive the message. This illustrates a key difference in how messages are handled in Camunda BPM vs Zeebe.
In Camunda BPM, if a message is published and the token from the workflow instance that the message will the correlated with has not yet arrived at the message catch event or receive task, the message is simply dropped. And unless the message is re-published at some point, the workflow instance could remain stuck at the message event forever.
In Zeebe, however, a message can be buffered even if the workflow instance token has not yet arrived at the message catch event or receive task. When the token does eventually arrive at the message event, it’ll check for a matching message, and if the message already exists, it’ll be correlated with the workflow instance. If no matching message is present when the token arrives at the event, the workflow instance will open a subscription until a message arrives.
What happens to a buffered message that can’t be correlated with a workflow instance? That’s where Zeebe’s new message time-to-live (TTL) feature comes in. A message can be correlated with a workflow only within the message TTL, after which the message will be dropped from the buffer. It’s possible to set the TTL to 0 if you’d like a message to be discarded if it can’t be correlated to a workflow instance immediately–thus replicating Camunda BPM’s message behavior.
Partitions are Zeebe’s primary scalability mechanism, and it’s possible that a message could be published to one partition, while the workflow instance(s) that Zeebe will correlate the message to is on a different partition. Good news: we thought of this when designing the message correlation feature, and a workflow instance will always know which partition to subscribe to in order to find a message. In other words, you, the user, don’t have to do anything to make sure that the workflow instance subscribes to the correct partition so that it can receive the message–Zeebe takes care of it behind the scenes.
One last thing we’ll note about message correlation in Zeebe: in Zeebe, a single message will be correlated to more than one workflow instance in a case where more than one workflow instance shares the same correlation information.
This behavior in Zeebe more closely resembles message behavior in systems like Kafka, where messages can be (and often are) consumed by multiple services and have no default “single receiver” characteristic. Based on user feedback, we might in the future add a message parameter where the user can specify how many times a single message can be correlated to a workflow instance–and if this parameter was set to 1, a message would only be correlated to one workflow instance.
Speaking of Kafka, can Zeebe work with messages published to an Apache Kafka topic?
The quick answer: yes! In fact, we dedicated an entire presentation to this subject at Kafka Summit San Francisco in October 2018. To learn more, you can watch the talk here.
And while we don’t yet offer an “official” Kafka-Zeebe connector as part of the Zeebe project, the demo code used in the presentation is publicly available in this GitHub repository from Camunda co-founder Bernd Rücker.
The ability to use Zeebe alongside Kafka and other message queues is an important consideration in the world of microservices architectures, and we’ve been thinking about Kafka + Zeebe use cases as we design the product. In the future, we’ll provide documentation and other resources to help users understand how to best combine the two systems.
Getting started with messages in Zeebe
Next, let’s cover how to start working with messages in Zeebe. If you download the most recent version of the Zeebe Modeler, you’ll see that the receive task and intermediate message catch event are available for modeling in the left-side toolbar.
If you include a receive task or intermediate message catch event in a model, you’ll need to set two fields in the Properties panel: the message name and the subscription correlation key. You’ll include these fields in the messages that you send, too, as these are what make it possible to correlate a message to the correct workflow instance(s).
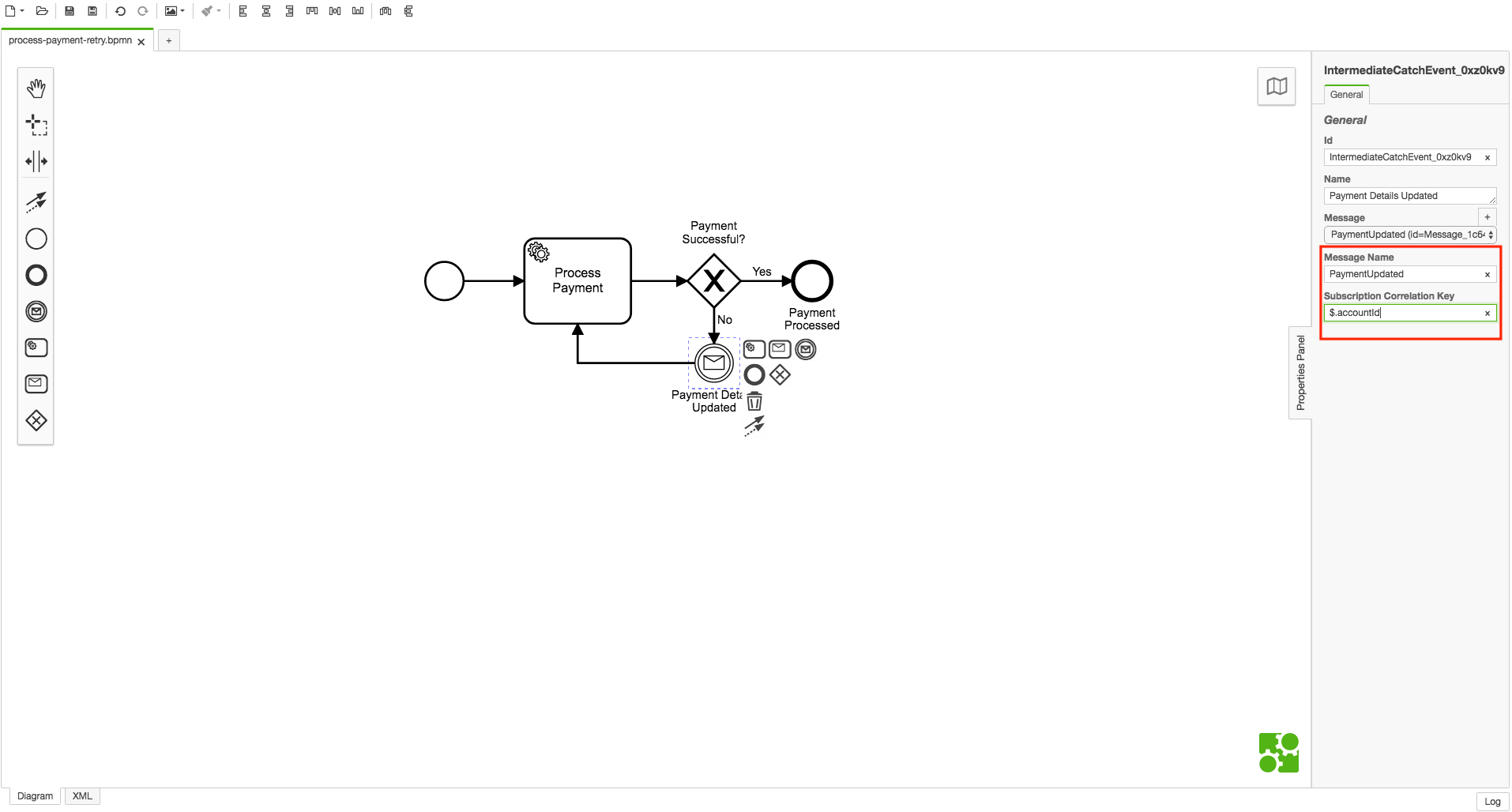
It’s also necessary to include the correlation key in your workflow instance payload–again, without this key, it won’t be possible to correlate a workflow instance with a buffered or incoming message. The Data Flow section of the Zeebe documentation covers the workflow instance payload in detail.
Currently, messages can be published using one of Zeebe’s clients (and as we mentioned, it’s also possible for Zeebe to ingest a message from a Kafka topic). Let’s look at how to publish a message with Zeebe’s Java client.
Below, we see a message with name PaymentUpdated (the same message name we defined for our intermediate message catch event in the Zeebe modeler), the correlation key account-123 (remember, we set accountId as our correlation key in the Zeebe modeler), a TTL of 30 minutes, and a payload of paymentMethod : Visa. In the message, this payload value could be any arbitrary data that we want to include in the workflow instance payload after the message is correlated.
workflowClient
.newPublishMessageCommand()
.messageName("PaymentUpdated")
.correlationKey("account-123")
.timeToLive(Duration.ofMinutes(30))
.payload("{"paymentMethod":"Visa"}")
.send()
.join();We’ll be adding more detail to the docs about how to work with messages with Zeebe’s client’s in the future–and be sure to reach out with any questions in the meanwhile.
Wrapping up
We’re really excited about the use cases enabled by Zeebe’s message support in 0.12, and we’re currently working on additional message functionality for upcoming releases. Interrupting and non-interrupting message boundary events are in progress in Q4 2018 and will vastly expand the business logic that can be expressed in Zeebe.
In time, we’ll provide more guidelines and best practices for working with messages, and we’re excited to see what the community builds with these features.
Lastly, here’s a quick rundown of next steps you can take if you want to learn more about messages in Zeebe or start to get hands on:
- Read about message events or receive tasks in the documentation
- Read our reference guide about Message Correlation in the documentation
- Watch Bernd Rücker’s Kafka Summit SF 2018 talk “The Big Picture: Monitoring and Orchestration of Your Microservices Landscape with Kafka and Zeebe”
- Download the Zeebe Modeler and build a sample workflow model using a message event or receive task
