
When checking in for a flight online, normal people hope that everything works the way it’s supposed to. That usually means no error messages, and at the end of the process, getting a boarding pass in your selected format.
We at Camunda, however, are not “normal people”.
A problem during check-in is a bit of a thrill for us because it gives us a peek into how a company handles software failures in a high-traffic application.
We never know exactly what’s happening under the hood, of course, but we like to speculate.
“Ah, yes, looks like they’re taking a ‘fail fast’ approach and have implemented something like a circuit breaker to isolate the issue.”
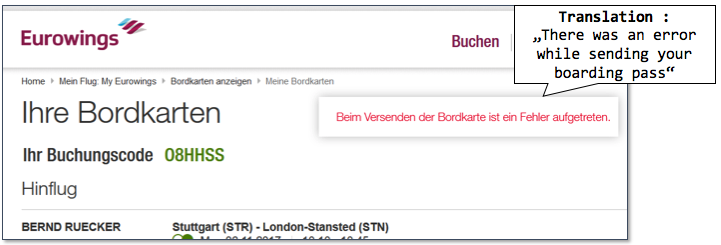
“Oh, brutal. 10 bucks says it’s a cascading failure.”
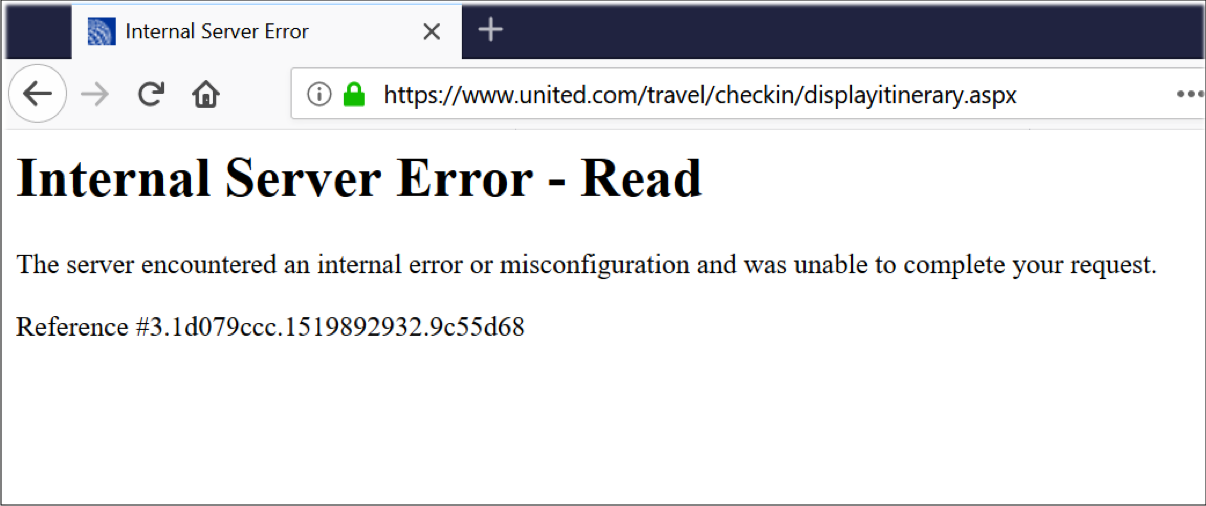
“Ah, they seem pretty confident they’ll have this figured out in a few minutes. And they really don’t want me bothering their customer support.”
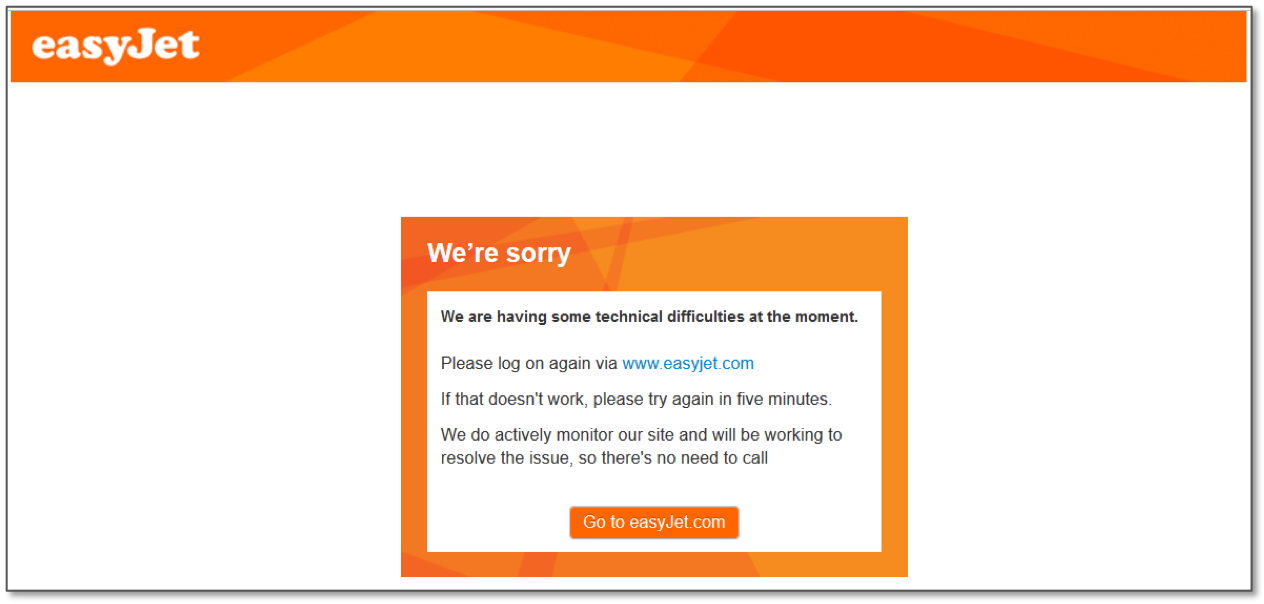
There’s one thing all three of these error messages have in common: the responsibility of handling the failure is pushed to the traveler. Sorry, not our problem anymore!
But it doesn’t have to be that way! After all, the airline should know the traveler’s flight details–these are usually submitted when first starting the check-in process–and it also probably has an email address associated with the booking. What’s stopping them from providing an error message like the one below (which we made up), promising to retry and send the boarding pass when it’s ready?
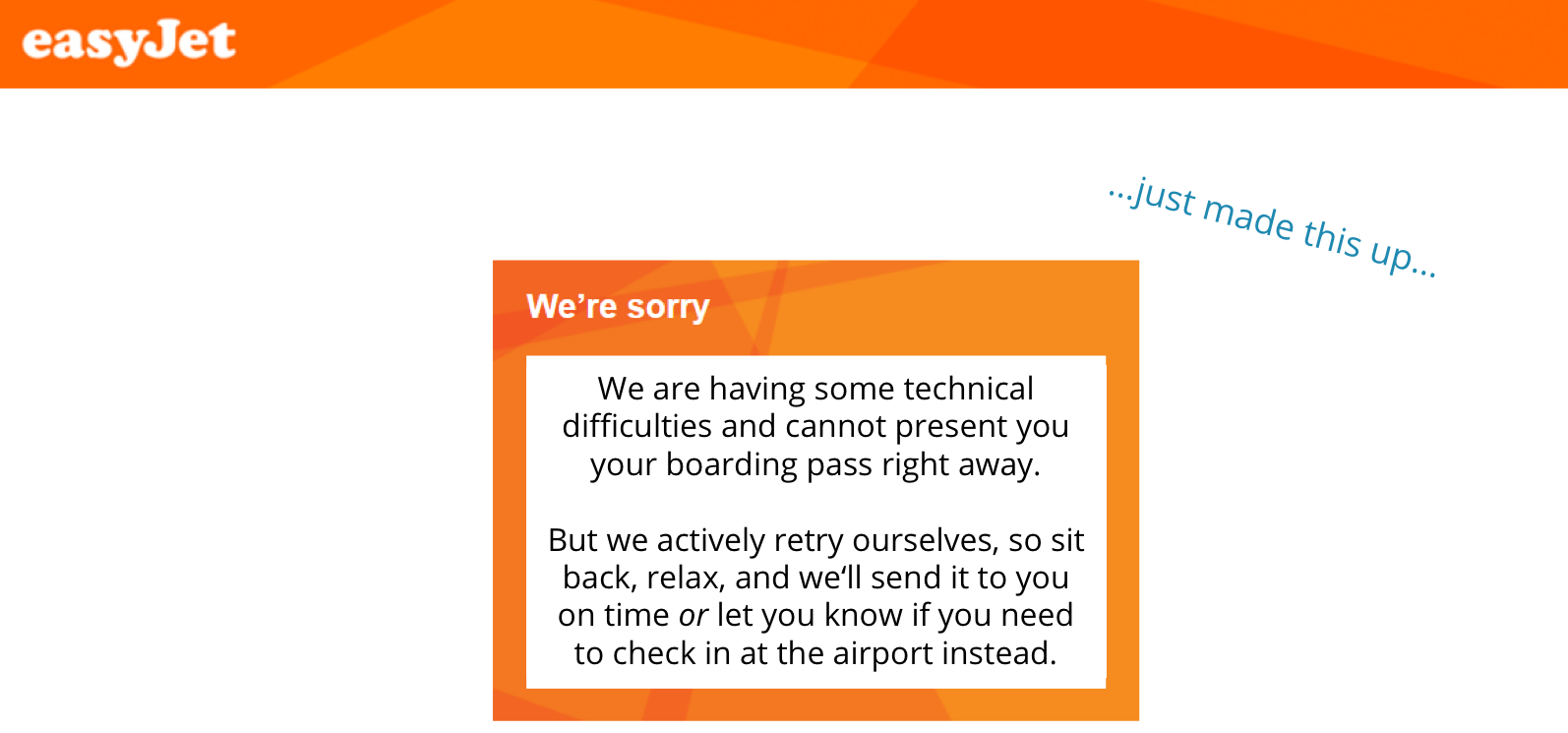
The answer probably has something to do with state.
When we say “state”, we’re simply referring to “information about what’s already happened up to this point in time in the application”. In this check-in example, an airline needs to be able to handle state to carry out the automatic retry that we described above. Said another way, the application needs to be able to refer to what’s already happened and use this information to decide what to do next–to “remember” the user’s flight and contact details, how far the user progressed in the check-in process, whether the user encountered an error, where in the check-in process the error occurred, and so on.
State handling is simple in concept, but implementing and then maintaining a homegrown solution to store state then build retry logic (and other business logic) on top of it is complicated–your application needs a “brain” that can persist data beyond a single connection, and it also needs some way to act on this data. We assume that’s why many developers decide not address the problem directly and instead pass a failure along to the client. Bernd has written about this once before, and given that it’s still a relevant topic, we want to revisit it in the context of Zeebe.
We’ve already spent some time describing how Zeebe is fault tolerant and how we ensure that Zeebe doesn’t lose any data (that is, workflow state) when there’s a failure. But we didn’t explicitly say why Zeebe’s ability to store and work with state so important in the first place–and that’s what we’re going to cover today.
We should say that we don’t know for sure if any given airline is using microservices when we see a check-in error message, but we know of some airlines that run on microservices, so we’re going to talk through an example in the context of a microservices architecture in the post. And the general concepts about failure handling apply regardless of the architecture.
We orchestrate because failure is inevitable
If we were confident that long-running, cross-microservice flows would always finish when they’re supposed to, free of any errors, then we probably wouldn’t be working on Zeebe in the first place. There’d be no need for a visibility and orchestration layer, and so long as messages had some way make it from one microservice to another, we’d have little to worry about. The existing communication toolkit, consisting of technologies like REST and messaging platforms like Apache Kafka, would probably be sufficient. And Netflix, Uber, Airbnb, ING, and other companies wouldn’t have needed to build open-source orchestration tools of their own.
But we’re aware of the fallacies of distributed computing, and we know that there’s indeed plenty that can go wrong in our distributed microservices architecture. Not to be all doom-and-gloom about it–we simply want to make sure we’re realistic about known challenges in our architecture and that we try to deal with them whenever we can.
This idea of designing for failure can exist in a few different dimensions, including but not limited to…
- Preventing local errors from bringing down the whole system (“fail fast”)
- Taking some sort of action to recover from an error and keep a process moving forward
We’ll focus on the second point today.
Boarding pass generation (a user-friendly approach)
Imagine we’re building services for the steps in the check-in process where a barcode is generated and a boarding pass is sent to the traveler in their desired format. In this example, every check-in that we need to handle is started by a message that we receive from an upstream system.
We can assume that when this message comes through, the customer’s travel details have already been validated, they’ve confirmed their phone number and email address, and they’ve specified the formats in which they want to receive their boarding pass (e.g. a mobile pass, an email with a PDF to print at home, etc). All of these details are included in the message payload.
There are two simple microservices that are involved in our process: one that generates a 3D barcode and one that sends the complete boarding pass to the customer in their selected format. We can model the process in BPMN like this:

We’re going to talk through how to modify our process model to add two user-friendly features here using Zeebe:
- Stateful retries in case either of our services fails, so that we can get the user their boarding pass on time without asking them to come back and go through the check-in process all over again.
- Sending a customer notification if we haven’t been able to successfully complete the check-in 4 hours prior to the flight, letting them know they’ll need to check in at the airport. No traveler is going to be happy about getting this message, but it’s better to know well in advance that the online check-in won’t be available so that you can plan accordingly.
Stateful retries in Zeebe: it really is that simple
This “stateful retry” functionality is built into Zeebe, and we’ll show you where. In the Zeebe Modeler, when you click on a service task, you’ll see a Retries field in the Properties panel. All you need to do is specify a number of retries, and Zeebe will handle the rest.
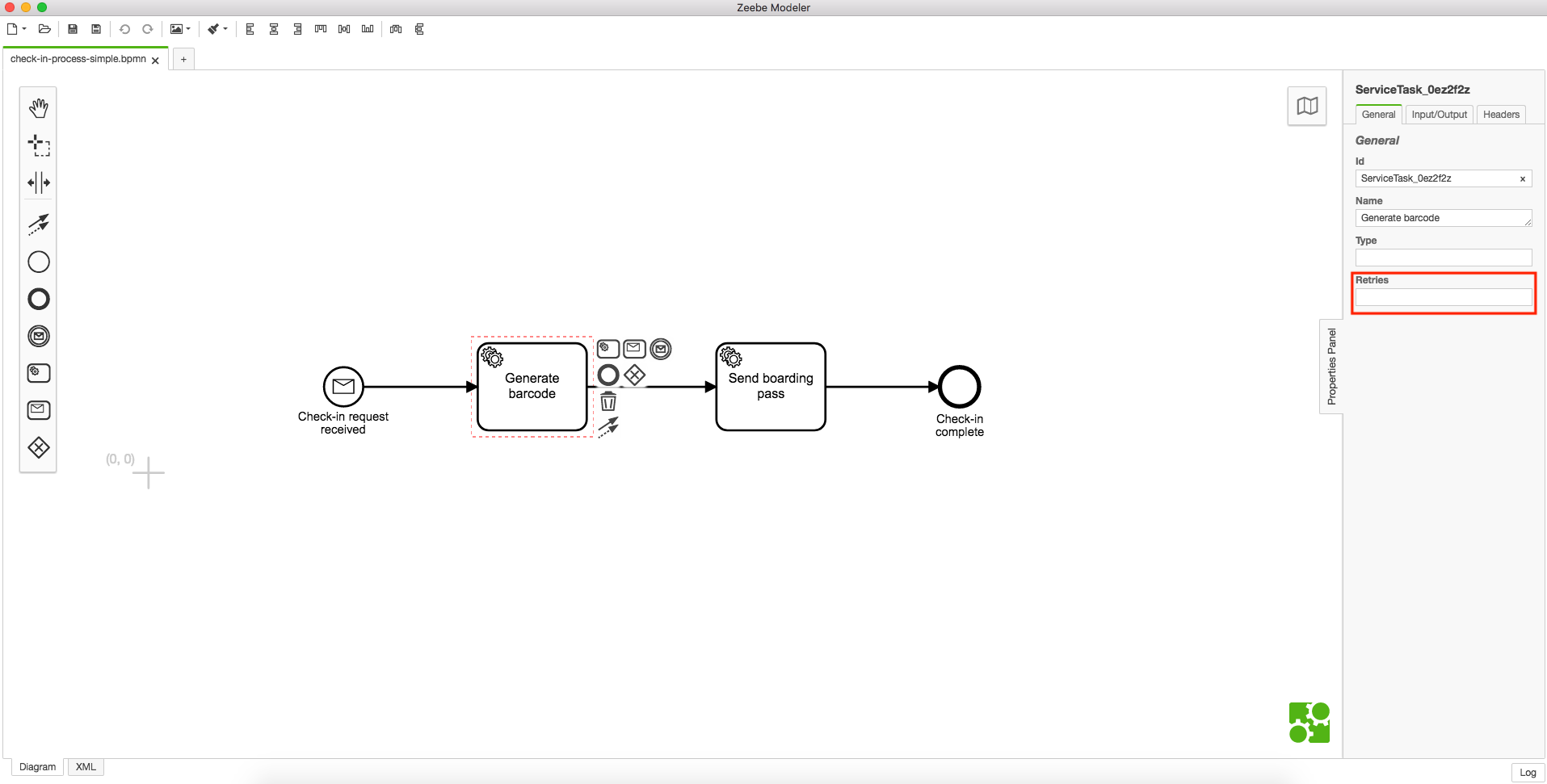
What’s most important, of course, is that these retries are stateful and will contain all of the necessary flight-related detail that was included in the customer’s original check-in attempt:
- Flight number and passenger name
- Contact info for sending the boarding pass
- Preferred boarding pass format
Also important is that this state is fault tolerant, meaning that if there’s a hardware or software failure that brings down a Zeebe broker, after we recover, we still know where in the process each active check-in is and still have all of that passenger detail listed above. This is where replications in Zeebe ensure that we have copies of our data on other brokers so that we can continue processing without losing our workflow state.
We mention this state handling capability fairly casually, as if it’s no big deal. And indeed, this functionality is exposed in Zeebe in a way that’s straightforward for the end user. But it’s worth saying again here: this is a feature that would be really difficult to build from scratch! At the least, you’d need a database component to manage every in-progress check-in as well as a scheduler component for the retries, both of which would need to be maintained over time (like any piece of proprietary software) and would need to be flexible enough to respond to any changes in the business logic itself.
That’s why a workflow engine is such an ideal fit for this state handling use case–it takes care of these tricky details for you.
Back to our process: we’ll now add an annotation to the BPMN model so it’s clear to everyone we’ve added a stateful retry to both tasks:
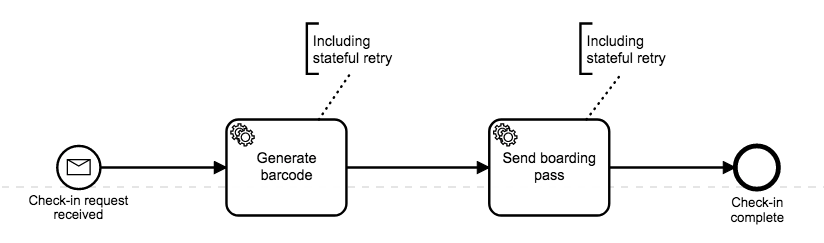
Nice job! We’re halfway there. But what happens in the case where our services haven’t recovered in time to get our traveler their boarding pass and we need to solve the problem some other way?
When it’s crunch time: requesting an in-person check-in
We’ll continue with our scenario where a traveler tried to check in but wasn’t able to do so because one or both of our services was unavailable. We showed them an error message promising that we’d try again on our own and send them a boarding pass once we were successful.
After a series of retries, our services still aren’t responding, and we haven’t been able to finish the check-in process on the traveler’s behalf. But the flight is coming up–we’re running out of time, and we need to take a different approach.
Luckily, there’s a BPMN element to handle this. Timer boundary event to the rescue!
The timer boundary event allows us to “interrupt” a task that is currently in-progress and follow some other path instead. Note that we don’t support this event in Zeebe yet, but we consider it a key symbol for automation use cases, and it’s on our near-term roadmap.
As for how we’ll put it to use: we decide it makes sense to send the traveler a message letting them know that, hey, sorry, but we couldn’t take care of your online check-in, and you’re going to have to do it at the airport. We’ll send this notification message 4 hours before the flight’s scheduled departure time to ensure the traveler can leave home early enough to check in at the desk.
In the model below, we’ve added timer boundary events to both of the original tasks in our workflow. Each of these events leads to a different service task where we’ll contact the customer via the phone number or email address they provided us when they initiated the check-in.
This customer notification is carried out by another simple service that we that introduced to our boarding pass generation process. The service either sends an SMS or makes an automated call to let the customer know they’ll need to check in at the airport. If we’re lucky, a notification service of this sort already existed somewhere in our broader application, and we can repurpose it for our use case.
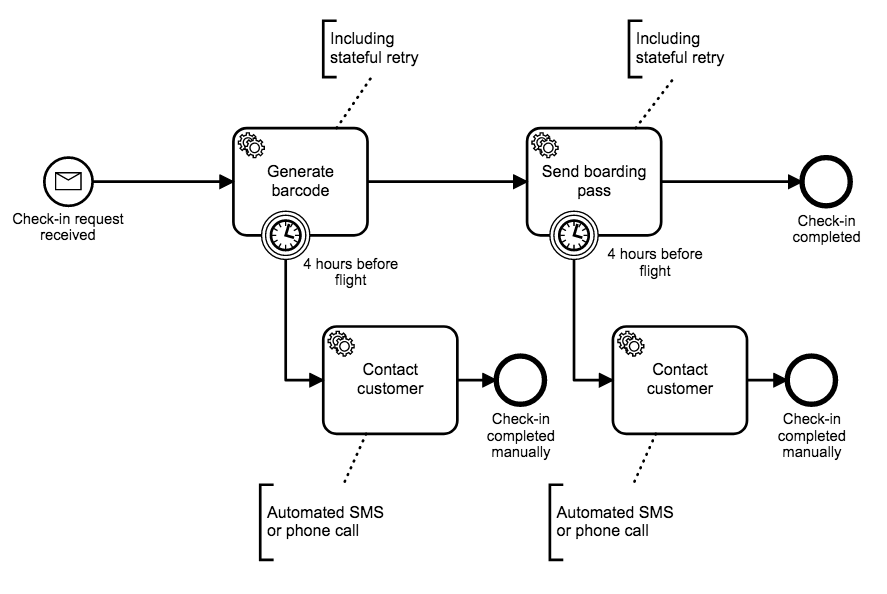
Congratulations! We’ve vastly improved our customer experience by taking responsibility for service failures, and we’ve done it almost entirely using a BPMN toolkit that was already available to us and easy to execute using a workflow engine like Zeebe.
Wrapping Up
The example we discussed today is one that we often refer to in talks and blog posts because it describes a scenario that’s simple and also relatable for just about anyone who’s reading what we’re writing. Of course, you can apply these same “stateful orchestration” concepts in Zeebe to much more complex models and in a range of different scenarios, too.
The broader points to take away are that:
- Failure is inevitable in a complex distributed system, and so we need to plan for it.
- When we can, we should take responsibility for failures and deal with them rather than passing them off to the end user.
- Taking responsibility for failures often requires managing state so that we can carry out retries, follow alternative process paths, and more.
- A workflow engine is one good way to manage state and apply business logic to this state without having to build and maintain a homegrown system.
If you’d like to give Zeebe a try, you can find installation instructions here. To ask questions or give feedback, visit the Community page, where you’ll find our community forum, public slack channel, and more. And to stay up to date on releases and other Zeebe news, you can sign up for our newsletter at the bottom of the Zeebe homepage.
